Path of a packet in the Linux Kernel Stack
1 INTRODUCTION
리눅스 커널 스택을 따라 움직이는 패킷의 흐름은 꽤 흥미로우며 성능 향상을 위한 연구 주제가 되어왔다.
이 문서는 2.6.11 버전의 리눅스 커널에 있는 TCP/IP 프로토콜 스택을 기반으로 하고 있다.
이 문서의 목표는 독자들이 커널내의 네트워크 패킷 흐름에 대해 익히도록 하는 것이다.(LXR을 통해 실제 커널내에서 기능을 수행하는 함수들을 살펴본다)
- Linux Cross-Reference (LXR)는 Hypertext Cross-referencing Tool로서 Function declarations, Data (type) definitions 그리고 Preprocessor macros를 쉽게 찾아갈 수 있게 도와주므로 대규모 Source Code를 분석하는데 많은 도움을 준다
이 문서는 네트워크 스택을 이해하기 위한 색인을 제공한다. 그리고 이것은 KURT DSKI를 포함한다. KURT DSKI는 커널내에서 패킷을 모니터링하는데 매우 유용하다
- KURT : Kansas University Real-Time project
- DSKI : Data Stream Kernel Interface
이 문서는 데이터를 소켓으로 전송하고 생성된 패킷의 경로가 코드를 통하여 추적되는 시나리오를 기반으로 한다.
2 TCP/IP - Overview
TCP/IP는 가장 흔한 네트워크 프로토콜이다. 이 프로토콜은 ISO의 OSI 표준이 수립되기 전 70년대부터 근간을 두고 있다. TCP/IP 프로토콜에서는 7개의 레이어 아키텍쳐를 감싸고 있는 4개의 레이어가 있다.
TCP/IP를 OSI 모델과 비교했을때 - TCP/IP의 어플리케이션 레이어는 OSI모델의 어플리케이션(Application), 프리젠테이션(Presentation), 세션(Session) 레이어로 구성된다.
소켓 레이어는 어플리케이션 레이어와 전송(Transport)레이어와의 사이에서 인터페이스 역할을 한다. 이 레이어를 트랜스포트레이어인터페이스(Transport Layer Interface)라고 부른다. 이 레이어에는 두가지 종류의 소켓이 있다고 언급할 가치가 있는데 그 중 하나는 연결 지향형 소켓(streaming socket)이고 다른 하나는 비연결형(datagram socket)이다.
다음 레이어는 TCP와 UDP를 기능적으로 포함하고 있는 트랜스포트(Transport)레이어이다. 이 레이어는 커널에서 TCP/IP스택의 4번째 계층을 형성한다. TCP/IP의 네트워크(Network)레이어는 IP 레이어라고도 부른다. 이 계층은 네트워크 토폴리지에 대한 정보를 담고 있으며 TCP/IP스택의 3번째 계층을 형성하며 주소 체계 및 라우팅 프로토콜에 대한 정보를 알고있다.
링크(Link) 레이어는 2번째 계층을 형성하고 오류 검출에 대한 처리를 한다. 오류 검출을 함으로써 신뢰있는 데이터 전송을 보장한다.
마지막 레이어는 물리(Physical)레이어이다. 여기서는 데이터 통신을 위한 다양한 전기 신호를 처리하는 책임을 가지고 있다.
3 When Data is sent through socket
리눅스 커널 내에서 네트워크 스택의 동작을 시각화 하기위해 TCP 소켓을 통해 패킷의 흐름을 살펴보자
3.1 Application Layer
네트워크 패킷은 사용자 프로그램에서 소켓에 데이터를 쓰게되는 어플리케이션 레이어에서 시작한다. 사용자 프로그램은 대부분 소켓 API를 사용한다. 소켓 API는 사용자가 소켓에 read, write를 하기 위한 시스템 콜을 제공한다. 소켓의 대부분 조작은 일반적인 파일과 비슷하다. 모든 주요 기능은 커널에서 추상화되어있다.
API는 사용자가 네트워크가 교류하기 위한 다양한 기능을 제공한다. 공통적인 몇가지 API로는 send, sendto, sendmsg, write, writev이 있다. 이들 중에서 send, write 그리고 writev는 함수를 호출 할때 목적지의 주소를 명시하는 부분이 없기 때문에 연결 지향형 소켓에서만 동작한다. write 시스템 콜은 3개의 인자를 갖는다.
write(socket, buffer, length);
writev는 write와 동일하게 동작하지만 어플리케이션이 메세지를 연속적인 메모리 공간에 복사할 필요 없이 여러개의 데이터를 묶어서 보낼 수 있도록 한다
writev(socket, iovector, vectorlen);
iovector는 메세지를 형성하는 여러 바이트들의 블록에 대한 포인터들의 시퀀스를 포함하는 iovec 타입의 배열 주소를 제공한다.
send, write..등등 메세지 전송 호출이 발생하면 net/socket.c에 있는 sock_sendmsg시스템 콜로 제어권이 넘어간다. 여기서 사용자의 버퍼를 읽을 수 있는지 체크하고 만약 읽을 수 있다면, 시스템 콜이 호출된 사용자 레벨 프로그램에서 사용할 소켓 디스크립터를 이용하여 소켓의 구조체를 가져온다. 그 다음 전송하기 위한 메세지와 프로세스의 UID, PID, GID에 대한 정보를 가지고 있는 소켓 제어 메세지를 기반으로하여 메시지 헤더를 생성한다. 이러한 모든 동작은 프로세스 컨텍스트 내에서 실행된다.
그 다음 어떠한 프로토콜에 맞는 sendmsg 함수를 호출할지 결정하는 __sock_sendmsg를 호출한다. proto_ops 구조체의 sendmsg 필드에서 프로토콜 옵션을 볼 수 있으며 프로토콜에 맞는 함수가 호출된다. 만약 TCP 소켓이라면 tcp_sendmsg 함수가 호출되고 만약 UDP 소켓이라면 udp_sendmsg함수가 호출된다. 이러한 결정은 제어권이 트랜스포트 레이어 인터페이스(Transport Layer Interface)로 넘어간 이후에 정해지고 이 과정에서 프로토콜 별로 호출하기 위한 함수를 결정한다.
tcp_sendmsg함수는 linux/net/ipv4/tcp.c에 정의되어 있고 사용자 프로그램에서 SOCK_STREAM 타입의 소켓을 이용하여 메세지를 전송할 때마다 호출된다.
3.2 The Socket Interface
소켓 인터페이스 레이어는 종종 어플리케이션 레이어와 트랜스포트레이어 사이에서 동작하는 접착제와 같은 역할을 한다. 이것은 또한 트랜스포트 레이어 인터페이스(Transport Layer Interface)라고도 불리며 소켓의 구조체를 추출하고 기능적으로 확인해야하는 책임을 가지고 있다. 실제로 이 레이어는 연결 형태에 대한 적절한 프로토콜을 처리하며 net/ipv4/af_inet.c에 있는 inet_sendmsg에서 실행된다.
이 계층에서는 다양한 소켓 생성과 관련하여 시스템콜을 변환하는 일도 한다. 소켓 생성에 대응하는 기능은 net/socket.c에서 실행된다. 이 곳은 bind, linsten, accept, connect, send, recv와 같은 소켓과 관련된 다양한 시스템 콜이 커널내에서 변환되는 지역이다.
KURT가 활성화된 커널에서 우리는 언제, 어떻게 시스템콜이 호출되는지에 대한 설명을 제공하기 위한 몇가지 플래그가 활성화 되는 것을 볼 수 있다.
- EVENT-SOCKET -> 소켓이 생성 되었을때
- EVENT_BIND -> 소켓이 주소에 바인딩 되었을때
- EVENT_LISTEN -> listen 함수가 호출 되었을때
- EVENT_CONNECT -> 클라이언트로 부터 connect 함수가 호출 되었을때
- EVENT_ACCEPT -> 클라언트로부터 서버가 커넥션을 Aaccept 했을때
- EVENT_SOCK_SENDMSG -> 소켓으로 메세지가 전송되었을때
- EVENT_SOCK_RECVMSG -> 소켓으로부터 메세지가 수신되었을때
이 계층에서는 더 많은 플래그가 존재한다. 자세한 내용은 kernel/scripts/dski/network.ns에 있는 network.ns를 참고하면된다.
소켓 레이어는 프로토콜의 종류를 구체화하고 프로토콜에 맞는 함수로 제어권을 넘기는 역할을 한다. 이 곳에서 프로토콜에 대한 구체화가 이루어지고 프로토콜에 맞는 트랜스포트레이어의 코드가 호출된다.
3.3 Transport Layer
메세지를 전송하기위한 프로토콜과 어떠한 함수를 호출할지 정해지게 되면 그 다음 부터의 모든 동작은 트랜스포트레이어에서 처리한다. proto 구조체에 셋팅된 함수포인터는 상황에 따라 tcp_sendmsg 혹은 udp_sendmsg를 가리키게 된다.
우리는 TCP를 다루고 있으니, tcp_sendmsg에 대해 살펴보자. tcp_sendmsg는 linux/net/ipv4/tcp.c에 정의되어 있고 패킷에 대해 TCP의 특정한 처리를 한다. TCP는 커넥션이 생성되지 않은 상태에서는 데이터를 전송할 수 없기 때문에 소켓 커넥션이 형성될때까지 대기하게 된다. 이와 관련된 코드는 아래에 있다. 타임아웃이 발생하기 전에 커넥션이 생성되어 있는지 체크를 한다.
/* Wait for a connection to finish. */
if ((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT))
if ((err = sk_stream_wait_connect(sk, &timeo)) != 0)
goto out_err;
커넥션에 대해 최대 세그먼트(Segment) 크기를 지정하는 일도 tcp_sendmsg에서 처리한다.
커넥션이 생성되게 되면, TCP와 관련된 동작들이 실행되고 실제 메세지 전송이 일어나게 된다. 유저 영역에서 커널 영역으로 데이터를 이동 시키기 위한 메커니즘인 IO 벡터 구조를 통하여 실행된다. 이 함수의 다른 부분에서는 struct sk_buff *skb를 생성하고 데이터를 유저 영역에서 커널 영역으로 복사한다.
tcp_sendmsg는 이미 할당된 버퍼에 충분히 사용 가능한 버퍼가 남아있는지 검사한다. 만약 충분히 남아있다면 데이터를 복사하고 그렇지 않다면 새로운 버퍼를 할당한다. 기본적으로 이 구조에서는 데이터를 소켓 버퍼로 복사를 시도하고 버퍼가 여의치 않다면 새로 할당한다.
소켓 버퍼가 데이터로 꽉 차게 되면 tcp_sendmsg는 skb_copy_to_page함수를 호출하여 데이터를 유저영역에서 커널 영역으로 복사한다. skb_copy_to_page는 커널 영역으로 데이터를 복사하기 전에 내부적으로 체크섬(checksum)을 계산한다. 이 외에도 tcp_sendmsg에는 오류 처리를 위한 다른 기능도 포함되어있다. 마지막으로 tcp_push_one함수를 호출한다. 이 함수는 tcp_transmit_skb를 호출하기 함수들 중 하나인데, tcp_transmit_skb는 TCP 세그먼트를 실질적으로 전송하는 함수이다. tcp_transmit_skb를 호출할 수 있는 다른 함수들은 아래와 같다.
extern int tcp_write_xmit(struct sock *, int nonagle);
extern int tcp_retransmit_skb(struct sock *, struct sk_buff *);
extern void tcp_xmit_retransmit_queue(struct sock *);
extern void tcp_simple_retransmit(struct sock *);
and so on ...
tcp_transmit_skb는 패킷을 IP레이어로 전송한다. 이 함수는 TCP 헤더를 생성하고 패킷을 IP레이어로 보낸다. 헤더를 만든다는 것은 출발지, 목적지의 IP주소와 TCP 시퀀스 번호를 셋팅하는 것을 의미한다. 여기서 tcphdr라는 것이 상대적으로 중요한 요소인데, 이것은 헤더 정보를 담고 있는 tcp_skb_cb를 가지고 있다. tcp_skb_cb는 TCP 헤더의 여러가지 플래그들을 포함하고 있는 TCP 제어 구조체이다.
tcp_transmit_skb는 위 역할 외에도 TCP 윈도우 스케일 옵션(TCP Window Scale option)을 지정한다. 체크섬(checksum) 계산 값은 데이터 부분 혹은 헤더 부분에 추가된다. 마지막으로 queue_xmit함수가 호출되는데 이 것은 패킷을 목적지로 보내기 위해 큐에 쌓는다. 목적지는 내부일 수도 있고 외부일 수도 있는데 정확한 것은 다음 레이어에서 결정한다.
err = tp->af_specific->queue_xmit(skb, 0);
if (err <= 0)
return err
/* where tp is the tcp_sock structure */
리턴 값이 0 이하인 것은 패킷이 버려진 것을 의미한다. KURT가 활성화 되어있으면 다음과 같은 플래그들을 확인 할 수 있다.
- EVENT_TCP_SENDMSG -> tcp_send_msg가 호출 되었을때
- EVENT_TCP_WRITEXMIT -> tcp_write_xmit가 호출 되었을때
- EVENT_TCP_TRANSKB -> tcp_transmit_skb가 호출 되었을때
- EVENT_TCP_RECVMSG -> tcp 메세지를 수신했을때
- EVENT_TCP_DATA_QUEUE -> tcp_data_queue가 호출 되었을떄
이러한 모든 동작은 프로세스 컨텍스트 내에서 실행된다.
3.4 Network layer (IP)
IP 레이어는 패킷을 전달받은 후 IP헤더를 만든다. 이 레이어는 패킷의 경로 검색을 담당하고 패킷의 TTL(Time To Live) 정보를 유지한다. IP외에도 ICMP, IGMP가 IP레이어와 관련되어 있다. 이러한 프로토콜들은 IP의 일부라고 생각 할 수 있다. 이 레이어는 수신 패킷과 전송 패킷에 대하여 경로 검색을 동일하게 한다. 만약 전달된 패킷의 주소가 외부 주소라면 아래 층인 링크 레이어로 전달되고 수신된 패킷이 내부 주소로 전달된 경우 상위 레이어로 전달한다.
queue_xmit 함수가 호출 되었을때 제어권은 queue_xmit함수가 속해 있는 IP레이어가 갖게 된다. queue_xmit 함수는 /net/ipv4/ip_output.c에 선언되어 있다.
여기서는 FIB(Forwarding Information Base)를 이용한 포워딩과 라우팅 기능도 포함되어 있다. FIB는 주로 kern_rta구조체를 이용하여 처리되는데 여기서는 포워딩과 라우팅에 대한 언급은 하지 않는다.
__sk_dst_check를 이용하여 라우팅 정보를 확인한다. 필요에 따라 ip_fragment함수를 호출하여 패킷을 나눈다(fragment).
결국 라우팅 정보는 ip_route_output_flow를 호출하여 확인된다. ip_route_output_flow는 flowi구조체를 이용하여 패킷 라우팅을 처리하는 주 함수다. flowi 구조체에는 전송에 관련된 정보들이 담겨있다. /net/ipv4/route.c에 정의되어 있는 ip_route_output_flow는 ip_route_output_key를 호출한다. ip_route_output_key는 라우팅 정보를 찾고 flowi 구조체에 값이 있는지 확인한다. ip_route_output_key는 먼저 캐싱된 라우팅 정보에서 찾고 없을 경우 FIB(Forwarding Information Base)를 찾는다.
라우팅 검색을 빠르게 하기 위해 위에서 언급한 함수들이 호출된다. 그러나 라우팅 캐시와 FIB에서 라우팅 정보를 찾지 못할 경우 ip_route_output_slow함수가 호출 된다. ip_route_output_slow는 라우팅을 처리하는 함수이다. 여기까지의 과정 역시 프로세스 컨텍스트 내에서 처리된다.
라우팅 검색과 포워딩에 관한 복잡한 내용들은 설명을 명료하게 하기 위해 이 문서에 실지 않았다.
neighbour-cache 구조체 중 output 포인터에 값을 설정하게 되면 패킷에 대한 처리가 완료된다. 패킷에 대한 처리가 모두 완료되려면 다음 세가지중 하나가 발생할 수 있다.
- 패킷을 포워딩 하게 되면 output 포인터에는 ip_forward 함수를 지정한다.
- 패킷의 라우팅 정보과 확실치 않다면 output 포인터에는 ip_output 함수를 지정한다.
- 패킷의 라우팅 정보가 확실하다면 output 포인터에는 dev_queue_xmit 함수를 지정한다.
우리는 라우팅 정보가 확인되어 dev_queue_xmit 함수가 호출된다고 가정할 것이다.
3.5 Data Link Layer
데이터링크 레이어는 패킷을 디바이스로 건네주는 것을 제외한 많은 부분을 책임지고 있다. 이 계층은 도착한 패킷의 순서를 결정해주기 때문에 큐 레이어라고도 불리며 트래픽을 제어하는 함수들도 여기서 호출된다.
dev_queue_xmit함수는 외부 주소로 패킷을 보내야 할때 호출된다. 이 함수는 소켓 버퍼에 등록된 디바이스가 큐를 보유하고 있는지 확인하고 디바이스 큐의 락을 획득하기 전에는 Bottom Halt를 비활성화 시킨다.
dev_queue_xmit함수는 qdisc_run을 호출한다. 이 함수는 프로세스 컨텍스트 내에서 실행되며 디바이스가 전송해야할 패킷을 가지고 있는지 확인한다. 만약 패킷을 가지고 있다면 전송 시킨다. 만약 디바이스가 바쁜 상태라면 패킷을 전송하기 위해 이 함수는 Soft IRQ 컨텍스트 내에서 다시 실행된다.
프로세스 컨텍스트에서 queue_disc함수가 호출되면 이 함수는 netif_queue_stopped 함수를 통하여 디바이스의 상태를 확인한다. 만약 그 함수가 디바이스가 활성화 상태라고 확인하게되면 프로세스 컨텍스트내에서 qdisc_restart함수를 호출하여 패킷 전송을 시도한다. 먼저 디바이스에 대한 xmit_lock을 획득하기 위해 시도하고 만약 락을 획득했을 경우 시스템 외부로 패킷을 전송하는 dev->hard_start_xmit함수를 호출하게 된다. dev->hard_start_xmit는 디바이스 드라이버 코드에 따라 다르게 구현되어있다.
패킷은 하드웨어로 패킷을 복사하고 전송하기 위한 IO명령들을 통해 외부로 전송된다. 패킷 전송이 완료되면 디바이스는 하드웨어 내에서 패킷에 할당했던 sk_buff 공간을 해제하고 전송한 시간을 기록한다.
만약 어떤 이유로 전송이 실패하게 되면 패킷을 재전송하기위해 큐에 넣는다. 이 과정은 qdisc_restart 함수의 오류 처리 과정에서 실행된다. 어떤 이유로 패킷 전송이 되지 않은 경우, netif_schedule함수가 호출된다. 이 함수는 Soft IRQ 컨텍스트 내에서 패킷 전송을 다시 스케쥴링한다. netif_schedule함수는 __netif_schedule함수를 호출하는데 이 함수는 전송을 시키기 위해 NET_TX_SOFTIRQ 이벤트를 발생시킨다.
결국 패킷은 다시 스케줄링되어 전송에 성공할 것이고 디바이스는 sk_buff를 해제한다. 그리고 디바이스가 유휴 상태가 되었고 패킷을 더 전송할 수 있다는 것을 알리기 위해 netif_wake_queue함수를 호출한다. 이 함수는 다음 패킷에 대한 스케줄링을 하기 위해 SOFT IRQ를 발생시킨다.
어플리케이션에서 시작하여 패킷을 어떻게 송신 매체로 보내는지 알아보았다. 다음은 매체로 부터 패킷을 수신하였을때 프로세스가 어떻게 처리하는지 알아볼 것이다.
4 When data is received from the Medium
여기서는 물리적인 매체부터 어플리케이션 레이어까지 네트워크 패킷을 어떻게 다루는지 살펴본다. 패킷을 수신하는 과정은 전송하는 것보다 훨씬 더 복잡하다.
4.1 Physical layer
패킷이 NIC(Network Interface Card)에 도착하게 되면 NIC는 그 패킷을 수신하고 DMA(Direct Memory Access)를 통해 rx_ring으로 전달한다. rx_ring은 수신된 패킷을 DMA를 통해 이동시키는 커널 메모리 영역내에 있는 링 구조체이다. 데이터는 rx_ring구조체에 저장되고 sk_buff로 복사된다.
패킷이 커널 메모리로 이동되면 NIC는 CPU에게 인터럽트를 걸어 새로운 패킷이 들어왔다고 알려준다. 인터럽트를 받은 CPU는 패킷 처리를 담당하는 ISR로 제어권을 넘긴다. 인터럽트 컨텍스트내에서의 처리는 가능한 최소화해야하기 때문에 ISR은 패킷 처리를 위한 NET_RX_SOFTIRQ를 발생시킨다. 인터럽트 핸들러는 include/linux/netdevice.h에 선언되어 있는 __netif_rx_schedule를 호출하고 이 함수는 다시 __netif_rx_schedule 함수를 호출한다.
__netif_rx_schedule 함수는 디바이스에대한 참조를 soft-net_data 폴링 리스트에 넣고 NET_RX_SOFTIRQ를 스케쥴링한다. 여기부터 패킷 처리에 대한 제어권은 soft irq 컨텍스트가 가지게된다.
NET_RX_SOFTIRQ를 처리할때 마다 net_rx_action 함수를 호출한다. 이 함수는 net/core/dev.c에 선언되어 있다. net_rx_action 함수는 각 디바이스의 rx_ring에 있는 모든 패킷을 처리 할때까지 인터럽트를 비활성화 시킨다. 이 함수는 각 디바이스를 폴링하고 각 디바이스의 rx_ring을 처리한다. include/linux/netdevice.h에 선언되어있는 net_device 구조체에는 폴링하기 위해 /net/core/dev.c에 정의되어 있는 process_backlog를 가르키는 함수 포인터를 가지고 있다.
backlog_dev는 임시 디바이스 정보이다. 디바이스 드라이버가 netif_rx함수를 호출하였는데 폴링 리스트에 backlog_dev가 없을 경우 리스트에 추가된다. 이것은 input_pkt_queue에 들어온 패킷을 제거하기위한 동작이다. process_backlog를 가리키고 있는 backlog_device의 폴링 함수는 큐에서 패킷을 제거하고 처리하기 위해 호출된다.
그러므로 net_rx_action함수가 각 디바이스를 폴링 할때마다 결국은 패킷을 처리하기 위한 process_backlog함수가 호출된다.
process_backlog함수는 패킷을 __skb_dequeue함수를 통하여 디바이스의 큐에서 꺼낸 후 sk_buff구조체로 옮긴다. 그리고 추가적인 처리를 위해 netif_receive_skb함수를 호출한다.
netif_receive_skb 함수는 패킷의 타입에 따라 분류하고 적절한 패킷 핸들러 함수로 보내준다. 예를 들어 IP 패킷일 경우 ip_rcv 함수를 호출 한다.
4.2 Network Layer - IP
패킷을 수신하는 주 함수는 ip_rcv이다. 이 함수는 패킷의 오류를 체크하고 IP헤더를 지운다. 필요에 따라 분할된 패킷들은 다시 하나로 모은다. 패킷은 몇 단계를 거쳐 net/ipv4/ip_input.c에 정의되어 있는 ip_rcv_finish함수에 도착한다.
ip_rcv_finish은 패킷에 대해 라우팅 검색을 실시하여 이 패킷이 자신에게 온 것인지 혹은 포워딩해야 하는 것인지 결정한다. 그리고 만약 자신에게 온 것이라면 dst_input함수가 호출되는데 이 함수는 다시 ip_local_deliver함수를 호출한다. ip_local_deliver함수는 /net/ipv4/ip_input.c에 선언되어 있고 필요에 따라 나뉘어진 패킷을 다시 합친다. 그리고 ip_local_deliver_finish를 호출한다. ip_local_deliver_finish은 패킷을 처리하기위한 적절한 함수를 호출하게 된다.
ip_local_deliver_finish함수는 IP헤더를 벗겨내고 프로토콜 숫자에 기반한 해쉬 함수를 이용하여 어떤 프로토콜인지 분별한다. 프로토콜 종류에 따라 각 핸들러가 호출된다. 만약 TCP 프로토콜이라면 tcp_v4_rcv함수가 호출될 것이다. 이 것은 트랜스포트 레이어로 패킷이 이동된 것을 의미한다.
4.3 Transport Layer
TCP는 inet_protocol 구조체의 인스턴스를 초기화함으로써 핸들러 함수와 연결된다. tcp_v4_rcv함수가 핸들러에 셋팅된다.
tcp_v4_rcv함수는 linux/net/ipv4/tcp_ipv4.c에 선언되어 있는데 이 함수는 IP헤더에 TCP 프로토콜 숫자(6)이 포함되어 있을때 호출된다.
이 함수는 패킷이 유효한 TCP 헤더를 가지고 있는지 pskb_may_pull함수를 통하여 확인한 후 TCP 헤더에서 몇몇 필드를 추출하여 체크섬을 계산한다.
내부적으로 소켓 버퍼에서 TCB(TCP Control Buffer)를 가져오기 위해 TCP_SKB_CB매크로를 이용한다.
TCB에는 ack와 같은 상태를 가르키는 파라미터 그리고 TCP 시퀀스 번호 등이 있다.
이 함수의 다음 단계는 __tcp_v4_lookup호출을 통하여 수신된 패킷에 할당된 소켓을 찾는다.
sk = __tcp_v4_lookup(skb->nh.iph->saddr, th->source,
skb->nh.iph->daddr, ntohs(th->dest),
tcp_v4_iif(skb));
만약 할당된 TCP 소켓이 없는 경우 이 패킷은 버려진다. 유효한 TCP 소켓을 찾을 경우에만 패킷을 계속해서 처리한다. IP 보안과 관련된 파라미터들이 체크되고 연결이 TCP_TIME_WAIT 상태인지 체크한다. 만약 이 상태일 경우 늦게 도착한 TCP 세그먼트는 버려진다.
top half 컨텍스트에서 소켓인 락 상태인지, 만약 패킷을 더 이상 수용할 수 없는지, 디바이스의 backlog에 수신한 다른 패킷들이 추가되었는지 확인한다. 만약 락 상태가 아니라면 패킷은 prequeue구조체에 추가된다. 패킷이 prequeue구조체에 추가되면 패킷은 커널 컨텍스트가 아닌 프로세스 컨텍스트에서 처리될 수 있다. tcp_prequeue함수에 의하여 커널에서 사용자 영역으로 제어권이 이동한다. tcp_prequeue함수는 tcp_v4_rcv가 호출한다. 만약 tcp_prequeue가 0을 리턴하면 더이상 이 소켓과는 연관된 작업이 없다는 것을 의미한다. 이렇게 되면 tcp_v4_do_rcv를 호출한다.
tcp_prequeue는 include/net/tcp.h에 선언되어 있다. 그리고 이 함수는 대기중인 사용자 프로세스들을 위해 버퍼를 큐 처리하는 역할을 한다. 소켓이 데이터를 읽을 준비가 되어있으면 tcp_prequeue는 즉시 소켓의 prequeue를 처리한다. 이 함수는 사용자의 테스크가 소켓을 통한 데이터를 기다리고 있는지, prequeue 버퍼 처리를 기다리고 있는지 확인한다.
if (!sysctl_tcp_low_latency && tp->ucopy.task) {
__skb_queue_tail(&tp->ucopy.prequeue, skb);
tp->ucopy.memory += skb->truesize;
tcp_v4_do_rcv 함수가 호출되었을때 TCP연결이 연결된 상태인지 확인한다.(상태값이 TCP_ESTABLISHED인지 확인) 만약 연결이 정상적이라면 tcp_rcv_established함수가 호출된다.
tcp_rcv_established함수는 패킷을 처리하기 시작한다. 패킷이 정상적으로 수신되면 ACK를 전송하고 tcp_data_queue 함수를 호출한다. 이 함수는 소켓이 정상적으로 수신한 데이터 큐에서 데이터 세그먼트들을 큐에 담는다. 이 세그먼트들은 어플리케이션이 read 시스템 콜(tcp_recvmsg)을 호출 했을때 처리된다.
4.4 Application Layer
사용자 어플리케이션에서 read, recvfrom과 같은 API를 호출할 때 마다 그 API들은 /net/socket.c에 정의되어 있는 sys_recv 시스템콜이 호출된다. 이 시스템콜은 다시 sys_recvfrom을 호출한다.
sys_recvfrom과 다른 recv 시스템 콜들은 /net/socket.c에 정의되어 있는 sock_recvmsg를 호출한다. INET 소켓의 경우 sock_recvmsg는 /net/ipv4/af_inet.c에 정의되어 있다. 각 프로토콜에 맞는 수신 함수가 호출되는데 TCP의 경우 tcp_recvmsg가 호출된다.
모든 시스템 콜은 결국 linux/net/ipv4/tcp.c에 정의되어 있는 소켓 레이어의 tcp_recvmsg 함수로 오게 된다. 이 함수는 소켓 버퍼에서 유저 버퍼로 데이터를 복사한다. 또한 SIGURG 시그널에 의한 우선권을 갖는 데이터들 또한 여기서 처리된다. 기본적인 동작은 소켓버퍼에서 유저 버퍼로 지정된 바이트 크기만큼만 복사된다.
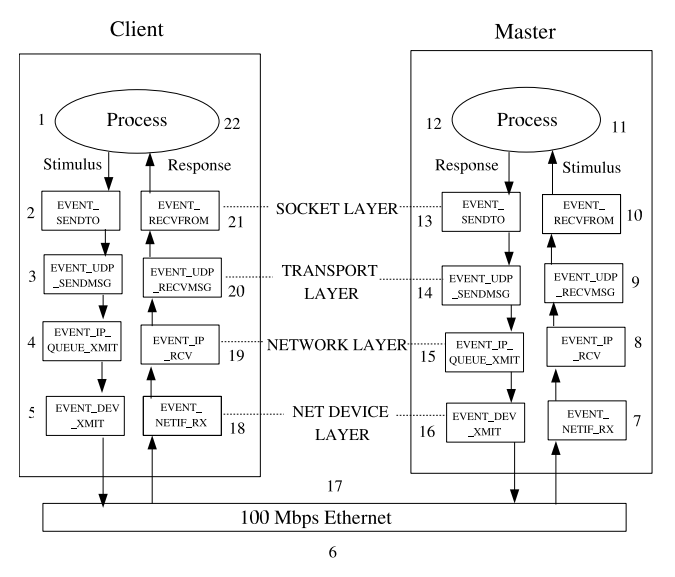
원문
- http://www.hsnlab.hu/twiki/pub/Targyak/Mar11Cikkek/Network_stack.pdf