Decision Tree
-분류 기술 중 가장 일반적으로 사용되는 방법
-과거에 수집된 데이터를 분석하여 속성의 조합으로 나타내는 분류모형을 트리 형태로 만드는 것
-만들어진 분류 모형(트리)은 새로운 데이터를 분류하고 해당 값을 예측하는데 사용
- 장점
- 계산 비용이 적다
- 학습된 결과를 사람이 이해하기 쉽다
- 누락된 값(missiong value)이 있어도 처리할 수 있다.
- 단점
- overfitting되기 쉽다
#의사결정트리 생성 방법
- 데이터를 분할하기 위한 ‘속성’을 결정한다.
- Information Gain이 가장 높은 속성을 결정한다.
- Entropy를 이용하여 정보획득량을 계산
- Entropy가 가장 높은 속성을 결정 한 후, 이 속성을 이용하여 데이터 분할
- 재귀적으로 트리 생성
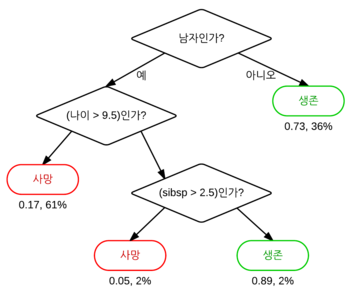 이미지 출처 : https://ko.wikipedia.org/wiki/결정_트리_학습법
이미지 출처 : https://ko.wikipedia.org/wiki/결정_트리_학습법
용어
- Overfitting ?
- Training Set에 맞춰서 생성되다 보니 테스트 집합이나 실제 분류되지 않은 데이터에 대해서는 큰 에러가 발생하는 문제
- Information Gain
- 데이터를 분할하기 전과 후의 엔트로피 변화량
- Entroypy
- Entroypy는 정보에 대한 기대 값으로 정의된다
- Entroypy를 계산하기 위해서는 분류 항목의 가능한 모든 값에 대해 정보의 기대값이 필요하다
- https://en.wikipedia.org/wiki/Entropy_(information_theory)
- Entroypy가 높다는 것은 데이터가 혼잡(?)하다는 것을 의미
예제
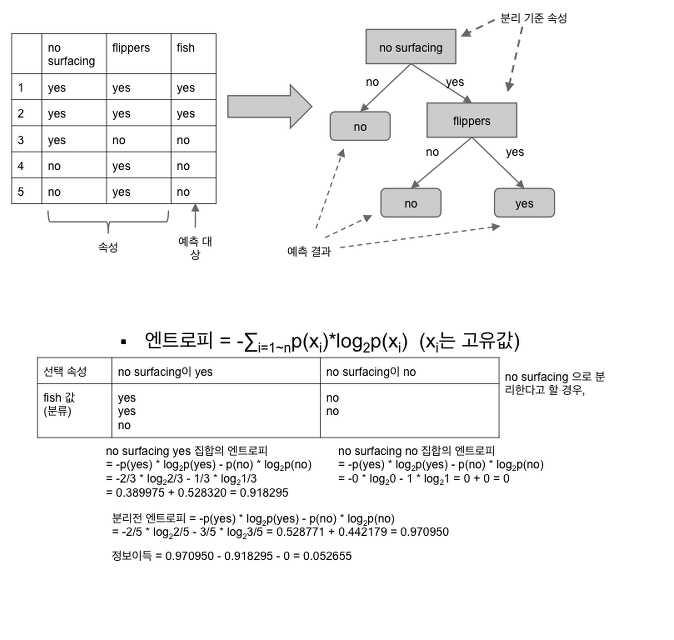 이미지 출처 : http://javacan.tistory.com/entry/MachineLearningInAction-03-DecisitionTree-ID3
이미지 출처 : http://javacan.tistory.com/entry/MachineLearningInAction-03-DecisitionTree-ID3
Published 03 July 2015