Effective Java
객체의 생성과 삭제
규칙1 생성자 대신 정적 팩터리 메서드를 사용할 수 없는지 생각해 보라
public static Boolean valueOf(boolean b) {
return b ? Boolean.TRUE : Boolean:FALSE;
}
- 클래스에 public으로 선언된 정적 팩터리 메서드를 추가하여 객체를 생성하는데는 다음과 같은 장점이 있다
- 생성자와는 달리 정적 팩터리 메서드에는 이름이 있다
- 생성자와는 달리 호출할 대마다 새로운 객체를 생성할 필요는 없다
- 생성자와는 달리 리턴 자료형의 하위 자료형 객체를 반환할 수 있다
- 형인자 자료형(parameterized type)객체를 만들때 편리하다
- 정적 팩터리 메서드를 사용하면 컴파일러가 형인자를 스스로 알아내도록 할 수 있다

- 정적팩터리 메서드만 있는 클래스를 만들게 되면 다음과 같인 문제가 발생한다
- public이나 protected로 선언된 생성자가 없으므로 하위 클래스를 만들 수 없다
- 정적 팩터리 메서드가 다른 정적 메서드와 확연히 구분되지 않는다
- API문서를 보면 생성자는 다른 메서드와 뚜렷이 구별되지만 정적 팩터리 메서드는 그렇지 않다
- Example
- valueOf : 인자로 주어진 값과 같은 값을 갖는 객체를 반환한다
- of : valueOf를 간단하게 쓴 것
- getInstance : 인자에 기술된 객체를 리턴하지만 인자와 같은 값을 갖지 않을 수도 있다
- newInstance: getInstance와 동일하지만 호출할 때마다 다른 객체를 반환한다
- getType : getInstance와 같지만 반환될 객체의 클래스와 다른 클래스에 팩터리 메서드가 있을때 사용한다. Type은 팩터리 메서드가 반환할 객체의 자료형이다
- newType : newInstance와 같지만 반활된 객체의 클래스와 다른 클래스에 팩터리 메서드가 있을 때 사용한다. Type은 팩터리 메서드가 반환할 객체의 자료형이다
규칙2 생성자 인자가 많을 때는 Builder 패턴 적용을 고려하라
규칙3 private 생성자나 enum 자료형은 싱글턴 패턴을 따르도록 설계하라
- 원소가 하나뿐인 enum자료형은 싱글턴을 구현하는 가장 좋은 방법이다
규칙4 객체 생성을 막을 때는 private 생성자를 사용하라
규칙5 불필요한 객체는 만들지 말라
- 객체 표현형 대신 기본 자료형을 사용하고 예상치 못한 자동 객체화가 발생하지 않도록 유의해야한다
- 객체를 만들어서 코드의 명확성과 단순성을 높이고 프로그램의 능력을 향상시킬 수 있다면 만드는 것이 좋다
- 객체 풀(Object Pool)을 만들어 객체 생성을 피하는 기법은 객체 생성 비용이 극단적으로 높지 않다면 사용하지 않는 것이 좋다
규칙6 유효기간이 지난 객체 참조는 페기하라
- 객체 참조를 null 처리하는 것은 규범이라기보단 예외적인 조치가 되어야 한다
- 자체적으로 관리하는 메모리가 있는 클래스를 만들 때는 메모리 누수가 발생하지 않도록 주의해야 한다
- 객체 참조를 캐시 안에 넣어 놓고 잊어버리는 일이 많기 때문에 캐시도 메모리 누수가 흔히 발생하는 장소다
- WeakHashMap을 이용하여 해결 가능
- 객체 참조를 캐시 안에 넣어 놓고 잊어버리는 일이 많기 때문에 캐시도 메모리 누수가 흔히 발생하는 장소다
규칙7 종료자(finalizer) 사용을 피하라
- 종료자는 즉시 실행되리라는 보장이 전혀 없다
- 종료자 실행시점은 GC 알고리즘에 좌우되는데 이 알고리즘은 JVM 구현마다 크게 다르다
- 종료자 실행시점에 의존하는 프로그램은 JVM마다 다르게 동작한다
- 종료자를 사용하면 프로그램 성능이 심각하게 덜어진다
모든 객체의 공통 메서드
규칙8 equals를 재정의할 때는 일반 규약을 따르라
- 모든 객체는 오직 자기 자신하고만 같고 아래 조건들 중 하나라도 만족되면 equals를 재정의하지 않아도 된다
- 각각의 객체가 고유하다
- 클래스에 “논리적 동일성” 검사 방법이 있건 없건 상관없다
- 상위 클래스에서 재정의한 equals가 하위 클래스에서 사용하기에도 적당하다
- 클래스가 private 또는 package-private로 선언되었고, equals 메서드를 호출할 일이 없다
- equals를 재정의하는 것이 바람직한 경우는 다음과 같다
- 논리적 동일성의 개념을 지원하는 클래스인 경우
- 상위 클래스의 equals가 하위 클래스의 필요를 충족하지 못하는 경우
- equals를 정의할 때 준수해야하는 일반 규약음 다음과 같다
- equals 메서드는 동치관계를 구현한다
- 반사성(reflexive) : null이 아닌 참조 x가 있을 때, x.equals(x)는 true를 반환한다
- 대칭성(symmetric) : null이 아닌 참조 x와 y가 있을 때, x.equals(y)는 y.equals(x)가 true일때만 true를 반환한다
- 추이성(transitive) : null이 아닌 참조 x, y, z가 있을 때, x.equals(y)가 true이고 y.equals(z)가 true이면 x.equals(z)도 true다
- 일관성(consistent) : 정보에 아무 변화가 없다면 x.equals(y) 호출 결과는 호출 횟수에 상관없이 항상 같아야 한다
- null이 아닌 참조 x에 대해서 x.equals(null)은 항상 false이다
- equals 메서드는 동치관계를 구현한다
- equals 메서드를 구현하기 위해 따라야하는 지침들은 다음과 같다
- ==연산자를 사용하여 equals의 인자가 자기 자신인지 검사하라
- instanceof 연산자를 사용하여 인자의 자료형이 정확한지 검사하라
- equals의 인자를 정확한 자료형으로 변환하라
- 중요 필드 각각이 인자로 주어진 객체의 해당 필드와 일치하는지 검사한다
- 너무 머리 쓰지 마라
- equals 메서드의 인자 형을 Object에서 다른 것으로 바꾸지 마라
규칙9 equals를 재정의할 때는 반드시 hashCode도 재정의하라
- equals 메서드를 재정의하는 클래스가 hashCode 메서드를 재정의 하지 않을 경우 Object.hashCode의 일반 규약을 어기게 되므로, HashMap, HashSet, Hashtable 같은 Hash기반 컬렉션이 오작동하게 된다
- 같은 객체는 같은 해시 코드 값을 가져야 하지만 hashCode를 재정의 하지 않으면 이 규칙을 위반 할 수 있다
규칙10 toString은 항상 재정의하라
- 가능하다면 toString 메서드는 객체 내의 중요 정보를 전부 담아 반환해야 한다
- toString이 반환하는 문자열의 형식을 명시하건 그렇지 않건 간에 어떤 의도인지는 문서에 분명하게 남겨야 한다
- toString이 반환하는 문자열에 포함되는 정보들은 전부 프로그래밍을 통해 가져올 수 있도록하라
규칙11 clone을 재정의할 때는 신중하라
- Cloneable은 객체가 복재를 허용한다는 사실을 알리는데 사용하려고 만들어진 mixin 인터페이스다
- Cloneable 인터페이스에는 clone 메소드가 없으며 Object의 clone 메서드는 protected로 선언되어 있다
- 실질적으로 Cloneable 인터페이스를 구현하는 클래스는 제대로 동작하는 public clone 메서드를 제공해야 한다
- clone 메서드는 또 다른 형태의 생성자다. 원래 객체를 손상시켜선 안되며 복사본의 불변식도 만족시켜야 한다
규칙12 Comparable 구현을 고려하라
클래스와 인터페이스
규칙13 클래스와 멤버의 접근 권한은 최소화하라
- 각 클래스와 멤버는 가능한 한 접근 불가능하도록 만들라
- private, package-private 멤버들은 클래스의 구현 세부사항이며 공개 API의 일부가 아니지만, Serializable을 구현하는 클래스의 멤버라면 공개 API속으로 포함되어 나갈 수도 있다
- 객체 필드는 절대로 public으로 선언하면 안 된다
- 변경가능 public 필드를 가진 클래스는 멀티 쓰레드에 안전하지 않다
규칙14 public 클래스 안에는 public 필드를 두지 말고 접근자 메서드를 사용하라
- package-private 클래스나 private 중첩 클래스는 데이터 필드를 공개하더라도 잘못이라 말할 수 없다
- 접근자 메서드보다는 시각적으로 깔끔해 보인다
- private 중첩 클래스의 경우 그 클래스의 바깥 클래스 외부의 코드는 아무 영향도 받지 않을 것이다
규칙15 변경 가능성을 최소화하라
- 변경 가능성을 최소화하는 것이 설계하기 쉽고 구현하기 쉽고 오류 가능성도 적고 안전하다
- 변경 불가능 클래스를 만드는 규칙
- 객체 상태를 변경하는 메서드를 제공하지 않는다
- 계승(상속)할 수 없도록 한다(클래스를 final로 선언한다)
- 모든 필드를 final로 선언한다
- 모든 필드를 private로 선언한다
- 변경 가능 컴포넌트에 대한 독점적 접근권을 보장한다
- 클래스에 포함된 변경가능 객체에 대한 참조를 클라이언트는 획득할 수 없어야 한다
- 변경 불가능 객체는 어떤 동기화도 필요없으며 쓰레드에 안전하다
- 변경 불가능 객체의 유일한 단점은 값마다 별도의 객체를 만들어야 한다는 점이다
- 객체 생성 비용이 높을 가능성이 있다. 이것을 해결하기 위해 다음 두가지 방법을 사용한다
- 자주 요구되는 연산에 대해서는 기본 연산(primitive)으로 제공한다
- 변경 가능한 public 동료 클래스를 제공한다
- String 클래스의 변경 가능 동료 클래스는 StringBuilder가 될 수 있다
- 객체 생성 비용이 높을 가능성이 있다. 이것을 해결하기 위해 다음 두가지 방법을 사용한다
규칙16 계승하는 대신 구성하라
- 메서드 호출과 달리 계승은 캡슐화 원칙을 위반한다
- 하위 클래스가 정상 동작하기 위해서는 상위 클래스의 구현에 의존할 수 밖에 없다
- 상위 클래스가 수정됨에 다라 하위 클래스 코드는 수정된 적이 없어도 망가질 수 있다
규칙17 계승을 위한 설계와 문서를 갖추거나, 그럴 수 없다면 계승을 금지하라
- 재정의 가능 메서드를 내부적으로 어떻게 사용하는지 반드시 문서에 남겨야 한다
- 효율적인 하위 클래스를 작성할 수 있도록 하려면 클래스 내부 동작에 개입할 수 있는 훅(hooks)을 신중하게 고른 protected메서드 형태로 제공해야 한다
- 생성자에서는 직접적이건 간접적이건 재정의 가능 메서드를 호출해서는 안 된다
- 상위 클래스 생성자는 하위 클래스 생성자보다 먼저 실행되므로 하위 클래스에서 재정의한 메서드는 하위 클래스 생성자가 실행되기 전에 호출될 것이다
- 계승을 위해 설계하는 클래스에서 Cloneable이나 Serializable을 구현하기로 결정했다면 clone이나 readObject 메서드도 생성자와 비슷하게 동작하므로 위 규칙을 따라야한다
- readObject메서드 안에서 재정의 가능 메서드를 호출하게 되면 하위 클래스 객체의 상태가 완전이 역직렬화(deserialize)되기 전에 해당 메서드가 실행되어 버린다
- clone 메서드의 경우라면 하위 클래스의 clone메서드가 복사본 객체의 상태를 미처 수정하기도 전에 해당 메서드가 실행되어 버릴 것이다
규칙18 추상 클래스 대신 인터페이스를 사용하라
- 인터페이스는 믹스인(mixin)을 정의하는 데 이상적이다
- 믹스인은 클래스가 주 자료형(primitive type)이외에 추가로 구현할 수 있는 자료형이다
- 추상 골격 구현(abstract skeletal implementatoin) 클래스를 중요 인터페이스마다 두면, 인터페이스의 장점과 추상 클래스의 장점을 결합할 수 있다
- 인터페이스로는 자료형을 정의하고 구현하는 일은 골격 구현 클래스에 맡기면 된다
- 관습적으로 골격 구현 클래스의 이름은 AbstractInterface와 같이 정한다
- Interface는 해당 클래스가 구현하는 인터페이스의 이름이다
- 추상 클래스로 정의하면 인터페이스보다 나은 점이 한 가지 있는데 인터페이스보다는 추상 클래스가 발전시키기 쉽다는 것이다
- 추상 클래스는 기본 구현 코드를 담은 메서드를 언제든 추가 할 수 있다
- 인터페이스가 공개되고 널리 구현된 다음에는 인터페이스 수정이 거의 불가능하기 때문에 신중히 설계해야한다
규칙19 인터페이스는 자료형을 정의할 때만 사용하라
규칙20 태그 달린 클래스 대신 클래스 계층을 활용하라
- 태그가 달린 클래스란 예를들어 특정 변수의 값에 따라 원을 표현할 수도있고 사각형을 표현할 수도 있는 클래스를 말한다
규칙21 전략을 표현하고 싶을 때는 함수 객체를 사용하라
- 가지고 있는 메서드가 하나 뿐인 객체를 함수 객체라고 부른다
- 실행 가능 전략이 한 번만 사용되는 경우에는 보통 익명 클래스 객체로 구현하고 반복적으로 사용된다면 private static 멤버 클래스로 전략을 표현한 다음 전략 인터페이스가 자료형인 public static final 필드를 통해 외부에 공객하는 것이 바람직하다

규칙22 멤버 클래스는 가능하면 static으로 선언하라
- 중첩 클래스는 해당 클래스가 속한 클래스 안에서만 사용되며 그렇지 않을 경우 중첩 클래스로 만들면 안 된다
- 중첩 클래스는 네 가지 종류가 있다
- 정적 멤버 클래스(static member class)
- 다른 클래스 안에 선언된 일반 클래스
- 바깥 클래스의 모든 멤버에(private 까지도) 접근할 수 있다
- 정적 멤버 클래스는 바깥 클래스의 정적 멤버이며 다른 정적 멤버와 동일한 접근 권한 규칙을 따른다
- 바깥 클래스 객체에 접근할 필요가 없는 멤버 클래스를 정의할 때는 항상 정적 멤버 클래스로 만들자
- 비-정적 멤버 클래스(nonstatic member class)
- 바깥 클래스 객체와 자동적으로 연결된다
- 비-정적 멤버 클래스 안에서는 바깥 클래스의 메서드를 호출할 수도 있고 this 구문을 통해 바깥 객체에 대한 참조를 획득할 수도 있다
- 바깥 클래스 객체 없이는 존재할 수 없다
- 비-정적 멤버 클래스 객체는 바깥 클래스 객체와 연결을 위한 공간이 필요하며 이 때문에 객체 생성 시간이 늘어난다
- 비-정적 멤버 클래스는 내부적으로 바깥 객체에 대한 참조를 유지하기 때문에 바깥 객체에 대한 GC처리가 힘들어진다
- 익명 클래스(anoynhymous class)
- 지역 클래스(local class)
- 정적 멤버 클래스(static member class)
제네릭
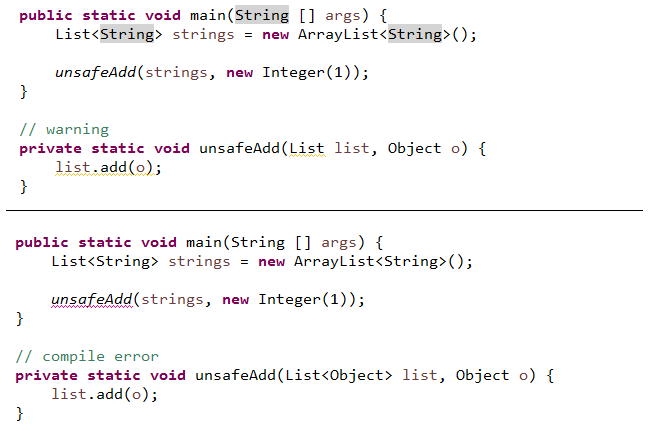
규칙23 새 코드에는 무인자 제네릭 자료형을 사용하지 마라
- 무인자 자료형을 쓰면 형 안전성이 사라지고 제네릭의 장점 중 하나인 표현력 측면에서 손해를 보게 된다
- List와 같은 무인자 자료형을 사용하면 형 안정성을 잃게 되지만 List<Object>와 같은 형인자 자료형을 쓰면 그렇지 않다
- List를 인자로 받는 메서드에는 List<String>을 인자로 전달 할 수 있지만 List<Object>를 받는 메서드에 List<String>을 인자로 넘길 수는 없다
- 제네릭에 대한 하위 자료형 정의 규칙을 따르면 List<String>은 List의 하위 자료형이지만 List<Object>의 하위 자료형은 아니기 때문이
- Collection<?>에는 null 이외의 어떤 원소도 넣을 수 없다
- null 이외의 어떤 원소도 넣을 수 없을 뿐 아니라 어떤 자료형의 객체를 꺼낼 수 있는지도 알 수 없다
- 제네릭 자료형 정보는 프로그램이 실행될 때는 지워지기때문에 다음 경우에는 무인자 자료형을 써야한다
- 클래스 리터럴에는 반드시 무인자 자료형을 사용해야 한다
- List.class, String[].class, int.class 는 가능
- List<String>.class, List<?>.class는 불가능
- 제네릭 자료형에 instanceof 연산자를 적용할 때는 무인자 자료형을 쓰는 것이 좋다
- instanceof 연산자는 비한정적 와일드카드 자료형 이외의 형인자 자료형에 적용할 수 없다
- 비한정적 와일드카드 자료형을 쓴다고해서 instanceof 연산자가 다르게 동작하는게 아니다. 따라서 <?>를 붙여봐야 코드만 지저분해질 뿐이다
- 클래스 리터럴에는 반드시 무인자 자료형을 사용해야 한다

규칙24 무점검 경고(unchecked warning)를 제거하라
- 제거할 수 없는 경고메세지는 형 안정성이 확식할 때만 @SuppressWarnings(“unchecked”) 어노테이션을 사용해라
- SupressWarning 어노테이션은 가능한 한 작은 범위에 적용하라
- 변수 선언, 아주 짧은 메서드 또는 생성자에 붙인다
- @SuppressWarnings(“unchecked”) 어노테이션을 사용할 때마다 왜 형 안정성을 위반하지 않는지 밝히는 주석을 반드시 붙여라
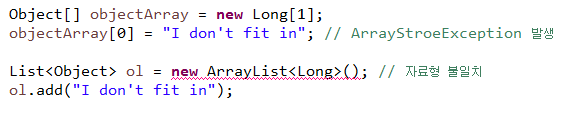
규칙25 배열 대신 리스트를 써라
- 배열은 공변 자료형(covariant)이지만 제네릭은 불변 자료형(invariant)이다
- 공변 자료형이란 Sub가 Super의 하위 자료형이라면 Sub[]도 Super[]의 하위 자료형이라는 것이다
- 불변 자료형이란 Type1과 Type2가 있을 때, List<Type1>은 List<Type2>의 상위 자료형이나 하위 자료형이 될 수 없다는 것이다
- 리스트를 사용하면 컴파일 시점에 오류를 알 수 있다
- 배열은 실체화 되는 자료형이지만 제네릭은 컴파일 시점에만 자료형이 적용되고 실행될 때는 자료형이 삭제된다
- 제네릭의 자료형이 실행될 때는 삭제되기 때문에 제네릭을 사용하지 않고 작성된 코드와도 연동된다
- 배열의 각 원소의 자료형은 실행시간에 결정된다
- 제네릭 자료형이나 형인자 자료형, 또는 형인자의 배열을 생성하는 것은 문법적으로 허용되지 않는다
- new List<E>[], new List<String>[], new E[]는 컴파일되지 않는 코드다
- 형 안정성이 보장되지 않기때문에 위 구문들이 허용되지 않는다
- 제네릭 자료형을 varargs 메서드와 함께 사용하면 복잡한 경고 메세지들을 보게 된다
- varargs 메서드를 호출할 때마다 varargs 인자들을 담을 배열이 생성되기 때문이다
규칙26 가능하면 제네릭 자료형으로 만들 것
규칙27 가능하면 제네릭 메서드로 만들 것
규칙28 한정적 와일드카드를 써서 API 유연성을 높여라
- PECS (Produce - Extends, Consumer - Super)

- 이 Stack 클래스는 Interable src가 가리키는 원소의 자료형이 스택 원소의 자료형과 일치하면 제대로 동작한다

- Integer는 Number의 하위 자료형이지만 제네릭은 불변(invariant)이기 때문에 위 코드는 오류가 발생한다
- pushAll의 인자 자료형을 “E의 Iterable”이 아니라 “E의 하위 자료형의 Iterable”이라고 명시하면 위 오류를 해결 가능하다


- 이 메서드는 컴파일 뿐 아니라 인자로 주어진 컬렉의 원소 자료형이 스택의 원소 자료형과 일치할 때는 완벽히 동작한다

- 위 코드는 Collection<Object>가 Collection<Number>의 하위 자료형이 아니라는 오류가 발생한다
- popAll의 인자 자료형을 “E의 컬렉션”이 아니라 “E의 상위 자료형의 컬렉션”이라고 명시하면 오류를 해결 가능하다

- 반환값에는 와일드카드 자료형을 쓰면 안 된다
- 클라이언트 코드 안에도 와일드카드 자료형을 명시해야 하기 때문이다
규칙29 형 안전 다형성 컨테이너를 쓰면 어떨지 따져보라
- 자바 1.5부터 Class가 제네릭 클래스가 되었다
- String.class의 자료형은 Class<String>이다
- Integer.class의 자료형은 Class<Integer>이다
- 아래 Favorite과 같은 클래스를 형 안전 다형성 컨테이너(typesafe heterogeneous container)라 부른다
- Favorite 클래스는 형 안정성을 보장한다
- String을 요청했는데 Integer를 반환하거나 하지 않는다
- Favorite 클래스는 다형성을 갖고 있다
- 일반적인 맵과 달리 모든 키의 자료형이 서로 다르다
- Favorite 클래스는 형 안정성을 보장한다

열거형(enum)과 어노테이션
규칙30 int 상수 대신 enum을 사용하라
- 일반적으로 enum은 int 상수와 성능 면에서 비등하다
- 자료형을 메모리에 올리고 초기화하는 공간적/시간적 비용 때문에 약간 손해를 볼 뿐이다
규칙31 ordinal 대신 객체 필드를 사용하라
- ordinal 값은 enum 필드가 추가되거나 삭제될때마다 변경 될 수 있다
- enum 상수에 연계되는 값을 ordinal을 사용해 표현하지 마라
- 그런 값이 필요하다면 객체 필드에 저장해야 한다

규칙32 비트 필드(bit field)대신 EnumSet을 사용하라
- 1 « 0, 1 « 1등 비트 필드로 나타내면 비트 단위 산술 연산을 통해 합집합이나 교집합 등의 집합 연산을 효율적으로 실행할 수 있다
- EnumSet 클래스는 enum 자료형의 값으로 구성된 집합을 효율적으로 표현 할 수 있다
- EnumSet 클래스는 내부젝으로 비트 벡터(bit vector)를 사용하며 enum 값 개수가 64개 이하인 경우 long 값 하나만 사용한다
- 위 이유로 1 « 0, 1 « 1과 같은 값을 int 자료형에 저장하여 처리하는 것과 필적하는 성능이 나온다
규칙33 ordinal을 배열 첨자로 사용하는 대신 EnumMap을 이용하라
규칙34 확장 가능한 enum을 만들어야 한다면 인터페이스를 이용하라
- 계승 가능 enum 자료형은 만들 수 없지만 인터페이스를 만들고 그 인터페이스를 구현하는 기본 enum 자료형을 만들면 계승 가능 enum자료형을 흉내 낼 수 있다
규칙35 작명 패턴 대신 어노테이션을 사용하라
- 과거 JUnit 테스트 프레임워크를 사용하려면 테스트 메서드 이름을 test로 시작해야 했는데 이러한 것을 작명패턴(naming pattern)이라 한다
- 작명패턴의 단점은 다음과 같다
- 철자를 틀리면 알아채기 어렵다
- 특정한 프로그램 요소에만 적용되도록 만들 수 없다
- testSafetyMechanisms라는 클래스를 만들었을 경우 JUnit이 이 클래스의 메서드 전부를 자동으로 실행하길 기대하지만 실제는 그렇게 동작하지 않았다
- 프로그램 요소에 인자를 전달할 마땅한 방법이 없다
규칙36 Override 어노테이션은 일관되게 사용하라
- 상위 클래스에 선언된 메서드를 재정의할 대는 반드시 선언부에 Override 어노테이션을 붙여야 한다
- abstract 클래스에서 abstract 메서드를 재정의할 때나 인터페이스를 구현할 때 Override 메서를 붙이지 않아도 된다
- 컴파일러가 오류를 발생 시킬 것이다
- 코드 인스펙션(code inspection)이라는 어노테이션 검사 기능을 갖춘 IDE를 사용할 경우 어노테이션을 일관되게 사용하면 좋다
- Override 어노테이션 없이 상위 클래스 메서드를 재정의하면 경고가 발생한다
- Override 어노테이션을 일관되게 사용하면 의도치 않게 메서드를 재정의하는 실수를 피할 수 있다
- 경고 메세지를 이용하여 실수로 상위 클래스 메서드를 재정의하는 실수도 피할 수 있다
규칙37 자료형을 정의할 때 표식 인터페이스를 사용하라
- 표식 인터페이스(marker interface)는 아무 메서드도 선언하지 않는 인터페이스다
- 클래스가 어떤 속성을 만족한다는 사실을 표현하고 싶을때 사용한다
- 표식 어노테이션과 비교했을 때 표식 인터페이스는 다음과 같은 장점이 있다
- 표식 인터페이스는 표식 붙은 클래스가 만드는 객체들이 구현하는 자료형이다
- 표식 어노테이션은 자료형이 아니다
- 표식 어노테이션보다 적용범위를 좀 더 세밀하게 지정할 수 있다
- 어노테이션을 정의할때 ElementType.TYPE으로 지정하면 어던 클래스나 인터페이스에도 적용이 가능하다
- 표식 인터페이스는 표식 붙은 클래스가 만드는 객체들이 구현하는 자료형이다
- 표식 어노테이션의 장점은 어노테이션 자료형을 쓰기 시작한 뒤에도 더 많은 정보를 추가할 수 있다는 것이다
- 기본값을 갖는 어노테이션 자료형 요소를 더해 나가면 된다
- 새로운 메서드가 없는 자료형을 정의하고자 한다면 표식 인터페이스를 이용해야 한다
- 클래스나 인터페이스 이외의 프로그램 요소에 표식을 달아야하고 앞으로 표식에 더 많은 정보를 추가할 가능성이 있다면 표식 어노테이션을 사용해야 한다
메서드
규칙38 인자의 유효성을 검사하라
- public 메소드라면 인자 유효성이 위반되었을 경웨 발생하는 예외를 Javadoc의 @throws 태그를 사용해서 문서화하라
- public이 아닌 메서드라면 개발자가 메서드 호출이 이루어지는 상황을 통제할 수 있으므로 assert 구문을 이용하여 검사하자
- java 인터프리터에 -ea 또는 -enableassertions 옵션을 주어야 assert 문이 처리된다

- 생성자는 나중을 위해 보관될 인자의 유효성을 반드시 검사해야 한다
- 유효성 검사를 실행하는 오버헤드가 너무 크거나 비현실적이고, 계산 과정에서 유효성 검사가 자연스럽게 이루어지는 경우는 유효성 검사를 미리 하지 않아도된다
- 무조건 인자에 제약을 두는 것이 바람직한 것이 아니다. 메서드는 가능하면 일반적으로 적용될 수 있도록 설계해야 한다
- 메서드가 받을 수 있는 인자에 제약이 적으면 적을수록 더 좋다
규칙39 필요하다면 방어적 복사본을 만들라
- 생성자로 전달되는 변경 가능 객체를 반드시 방어적으로 복사해서 사용하라
- 인자의 유효성을 검사하기 전에 방어적 복사본을 만들어라. 유효성 검사는 복사본에 대해 시행한다
- 인자를 검사한 후 복사본이 만들어지기전에 다른 쓰레드가 인자를 변경해 버리는 일을 막기 위함이다
- 인자로 전달된 객체의 자료형이 계승이 가능한 자료형일 경우(final 클래스가 아닌 경우) 방어적 복사본을 만들 때 clone을 사용해선 않된다
- clone 메서드가 반드시 인자 타입의 객체를 반환 할 것이라는 보장이 없다
- 공격을 위해 특별히 설계된 하위 클래스 객체가 반환될 수도 있다는 의미이다
- clone 메서드가 반드시 인자 타입의 객체를 반환 할 것이라는 보장이 없다
- 내부 필드를 리턴할때는 방어적 복사본을 생성하여 반환하도록한다
- 복사 오버헤드가 너무 크고 클래스 사용자가 그 내부 컴포넌트를 부적절하게 변경하지 않는다는 보장이 있을 때는 방어적 복사를 하는 대신 클라이언트 측에서 컴포넌트를 변경해서는 안 된다는 것을 문서에 명시하자
규칙40 메서드 시그니처는 신중하게 설계하라
- 메서드 이름은 신중하게 고르라
- 편리한 메서드를 제공하는 데 너무 열 올리지 마라
- 모든 메서드는 맡은 일이 명확하고 거기에 충실해야 한다
- 인자 리스트를 길게 만들지마라. 4개 이하가 되도록 노력하라
- 자료형이 같은 인자들이 길게 연결된 인자 리스트는 특히 더 위험하다
- 인자의 자료형으로는 클래스보다 인터페이스가 좋다
- 인자 자료형으로 boolean을 쓰는 것보다는 원소가 2개인 enum자료형을 쓰는 것이 낫다
- 좀 더 읽기 편한 코드가 만들어진다
규칙41 오버로딩할 때는 주의하라
- 오버로딩을 사용할 때는 혼란스럽지않게 사용할 수 있도록 주의해야 한다
- 혼란을 피하는 안전하고 보수적인 전략은 같은 수의 인자를 갖는 두 개의 오버로딩 메서드를 API에 포함시키지 않는 것이다
규칙42 varargs는 신중히 사용하라
- 가변인자(varargs)는 인자 수에 맞는 배열이 자동 생성되고 모든 인자가 해당 배열에 대입된다. 그리고 해당 배열이 메서드에 인자로 전달된다
- 가변인자는 정말로 임의 개수가 인자를 처리할 수 있는 메서드를 만들어야 할 때만 사용하라
- 가변인자는 인자 없이 메서드를 호출하는 것이 가능하고 인자의 유효성을 검사하는 코드를 명시적으로 넣어야한다
- 메서드가 인자를 두 개 받도록 선언하여 인자 없이 메서드 호출하는 것을 막을 수 있다

규칙43 null 대신 빈 배열이나 컬렉션을 반환하라
규칙44 모든 API 요소에 문서화 주석을 달라
- 좋은 API 문서를 만들려면 API에 포함된 모든 클래스, 인터페이스, 생성자, 메서드 그리고 필드 선언에 문서화 주석을 달아야 한다
- 제네릭 자료형이나 메서드에 주석을 달 때는 모든 자료형 인자들을 설명해야 한다
- enum 자료형에 주석을 달 때는 자료형이나 public 메서드뿐 아니라 상수 각각에도 주석을 달아야 한다
- 어노테이션 자료형에 주석을 달 때는 자료형뿐 아니라 모든 멤버에도 주석을 달아야한다
- Javadoc 유틸리티는 문서화 주석을 HTML 문서로 변환하니 참고하자
일반적인 프로그래밍 원칙들
규칙45 지역 변수의 유효범위를 최소화하라
- 지역 변수의 유효범위를 최소화하는 가장 강력한 기법은 처음으로 사용하는 곳에서 선언하는 것이다
- 거의 모든 지역 변수 선언에는 초기값이 포함되어야 한다
- 순환문 변수의 내용이 순환문 수행이 끝난 이후에는 필요 없을 경우 while 문보다는 for 문을 쓰는 것이 좋다
규칙46 for문 보다는 for-each문을 사용하라
- for-each문으로는 컬렉션과 배열뿐 아니라 Iterable 인터페이스를 구현하는 어떤 객체도 순회할 수 있다
- for-each문의 성능이 for문에 비해 뒤지지 않는다
- 다음 경우에 대해서는 for-each문을 적용할 수 없다
- 필터링(filtering)
- 컬렉션을 순회하다가 특정한 원소를 삭제할 필요가 있다면 반복자를 명시적으로 사용해야한다
- 변환(transforming)
- 리스트나 배열을 순회하다가 그 원소 가운데 일부 또는 전부의 값을 변경해야 한다면 원소의 값을 수정하기 위해서 리스트 반복자나 배열 첨자가 필요하다
- 병렬 순회(parallel iteration)
- 여러 컬렉션을 병렬적으로 순회해야 하고 모든 반복자나 첨자 변수가 발맞춰 나아가도록 구현해야 한다면 반복자나 첨자 변수를 명시적으로 제어할 필요가 있을 것이다
- 필터링(filtering)
규칙47 어떤 라이브러리가 있는지 파악하고 적절히 활용하라
- 중요한 새 릴리즈가 나올 때마다 많은 기능이 새로 추가되는데 그때마다 어떤 것들이 추가되었는지를 알아두는 것이 좋다
- 바퀴를 다시 발명하지 말라
규칙48 정확한 답이 필요하다면 flaot와 double은 피하라
- float와 double은 특히 돈과 관계된 계산에는 적합하지 않다
- 정확한 계산을 원하면 BigDecimal, int 또는 long을 사용해야한다
규칙49 객체화된 기본 자료형 대신 기본 자료형을 이용하라
- 객체화된 기본 자료형에 == 연산을 사용하는 것은 거의 항상 오류라고 봐야 한다
- 기본 자료형과 객체화된 기본 자료형을 한 연산안에 엮어 놓으면 객체화된 기본 잘형은 자동으로 기본 자료형으로 변환된다
- 객체화된 기본 자료형의 비객체화가 자동으로 일어나면서 NullPointerException이 발생할 수 있다
- 객체화된 기본 자료형이 성능 문제가 유발할 수 있다
규칙50 다른 자료형이 적절하다면 문자열 사용은 피하라
- 문자열은 값 자료형(value type)을 대신하기에 부족하다
- 문자열은 enum 자료형을 대신하기에는 부족하다
- 문자열은 혼합 자료형(aggregate type)을 대신하기엔 부족하다
규칙51 문자열 연결 시 성능에 주의하라
- n개의 문자열에 연결 연선자를 반복 적용해서 연결하는 데 드는 시간은 n^2에 비례한다
- 문자열은 변경 불가능하다
- 문자열 두 개를 연결할 때 그 두 문자열의 내용은 전부 복사된다
- 만족스런 성능을 얻으려면 String대신 StringBuilder를 사용하라
- StringBuilder는 StringBuffer에서 동기화 기능을 뺀것이며 StringBuffer는 이제 지원되지 않는다
규칙52 객체를 참조할 때는 그 인터페이스를 사용하라
- 적당한 인터페이스가 없는 경우에는 객체를 클래스로 참조하는 것이 당연하다
규칙53 리플렉션 대신 인터페이스를 이용하라
- 리플렉션을 아주 제한적으로만 사용하면 오버헤드는 피하면서도 리플렉션의 다양한 장점을 누릴 수 있다
- 일반적인 프로그램은 실행 중에 리플렉션을 통해 객체를 이용하려 하면 안 된다
규칙54 네이티브 메서드는 신중하게 사용하라
- 네이티브 메서드를 통해 성능을 개선하는 것은 추천하지 않는다
- 현재 JVM은 매우 빠르기에 네이티브 메서드 없이도 그에 필적하는 성능을 낼 수 있다
규칙55 신중하게 최적화하라
- 최척화 할 때는 다음 규칙을 따르라
- 규칙 1 : 하지마라
- 규칙 2 : 아직은 하지 마라 (완벽히 명료한 최적화되지 않은 해답을 얻을 때까지는..)
- 맹목적인 어리석음을 비롯한 다른 어떤 이유보다도 효율성이라는 이름으로 저질러지는 죄악이 더 많다 (William A. Wulf)
- 섣부른 최적화는 모든 악의 근원이다 (Donald E. knuth)
- 빠른 프로그램이 아닌 좋은 프로그램을 만들려 노력하라
- 설계를 할 때는 성능을 제약할 가능성이 있는 결정들은 피하라
- API를 설계할 때 내리는 결정들이 성능에 어떤 영향을 끼칠지를 생각하라
- 좋은 성능을 내기 위해 API를 급진적으로 바꾸는 것은 바람직하지 않다
- 최적화를 시도할 때마다 전후 성능을 측정하고 비교하라
규칙56 일반적으로 통용되는 작명 관습을 따르라
예외
규칙57 예외는 예외적 상황에만 사용하라
- 예외는 예외적인 상황에만 사용해야지 제어 흐름에 이용해서는 안 된다
- 잘 설계된 API는 클라이언트에게 평상시 제어 흐름의 일부로 에외를 사용하도록 강요해서는 안 된다
- Iterator 인터페이스에는 상태 종속적 메서드 next와 상태 검사 메서드 hasNext가 있다
- 상태 검사 메서드를 제공하기 싫다면 부적절한 상태의 객체에 상태 종속적 메서드를 호출하면 null같은 특이값이 반환되도록 구현하는 방법도 있다
- 외부적인 동기화 메커니즘 없이 병렬적으로 사요될 수 있는 객체거나 외부적인 요인으로 상태 변화가 일어날 수 있는 객체라면 특이값 방식으로 구현해야 한다
- 상태 검사 메서드를 호출한 다음 상태 종속적 메서드를 호출하기까지의 시간 동안 객체 상태가 변할 수 있기 때문이다
- 상태 종속적 메서드가 하는 일을 상태 검사 메서드가 중복해서 하는 바람에 성능이 떨어질까 우려된다면 역시 특이값 방식으로 구현해야 한다
- 외부적인 동기화 메커니즘 없이 병렬적으로 사요될 수 있는 객체거나 외부적인 요인으로 상태 변화가 일어날 수 있는 객체라면 특이값 방식으로 구현해야 한다
- 상태 검사 메서드를 제공하기 싫다면 부적절한 상태의 객체에 상태 종속적 메서드를 호출하면 null같은 특이값이 반환되도록 구현하는 방법도 있다
규칙58 복구 가능 상태에는 점검지정 예외를 사용하고, 프로그래밍 오류에는 실행시점 예외를 이용하라
- 호출자 측에서 복구할 것으로 여겨지는 상황에 대해서는 Checked 예외를 이용해야 한다
- UnChecked 예외에는 Runtime예외와 Error 두 가지가 있다
- 프로그램이 Runtiem예외 혹은 Error를 던진다면 복구가 불가능한 상황에 직면했다는 뜻이다
- 프로그래밍 오류를 표현할 때는 Runtime 예외를 사용하라
- Error는 더 이상 프로그램을 실행할 수 없는 상태에 돋라했음을 알리기 위해 사용한다
- 사용자 정의 UnChecked 예외는 RuntimeException의 하위 클래스로 만들어야 한다
- Throwable은 Checked 예외들과 동일하게 동작한다고 명시되어 있지만 절대로 활용하면 안 된다
- 일반적인 Checked 예외보다 나은 점이 없을 뿐더러 API 사용자를 혼란스럽게 한다
- Checked 예외는 일반적으로 복구가 가능한 상태를 나타내기 때문에 호출자 측에서 상태를 복구하는 데 이용할 정보를 제공하는 메서드를 갖춰 놓는 것이 중요하다
규칙59 불필요한 점검지정 예외 사용은 피하라
- Checked예외는 프로그래머로 하여금 예외적인 상황을 처리하도록 갖에함으로써 안정성을 높이지만 너무 남발하면 사용하기 불편한 API가 될 수 있다
- Checked예외를 UnChecked예외로 바꾸는 방법은 예외를 던지는 메서드를 둘로 나눠서 첫 번째 메서드가 boolean 값을 반환하도록 만드는 것이다

규칙60 표준 예외를 사용하라
- 배우기 쉽고 사용하기 편리한 API를 만들 수 있다
- 다른 프로그래머들도 친숙한 널리 퍼진 관습을 따르기 때문이다
- 가독성이 높다
- 메모리 요구량이 줄어들고 클래스를 로딩하는 시간도 줄어든다
- 일반적은 예외 예
- IllegalArgumentException
- null이 아닌 인자의 값이 잘못되었을 경우
- IllegalStateException
- 객체 상태가 메서드 호출을 처리하기에 적절치 않았을 경우
- NullPointerException
- null 값을 받으면 안 되는 인자에 null이 전달 되었을 경우
- IndexOutOfBoundsException
- 인자로 주어진 첨자가 허용 범위를 벗어났을 경우
- ConcurrentModificationException
- 병렬적 사용이 금지된 객체에 대한 병렬 접근이 탐지된 경우
- UnsupportedOpertaionException
- 객체가 해당 메서드를 지원하지 않는 경우
- IllegalArgumentException
- 예외를 발생시키는 조건은 예외의 문서에 기술된 것과 일치해야 하며 의미적으로도 재사용이 가능해야 한다
규칙61 추상화 수준에 맞는 예외를 던져라
- 상위계층에서는 하위계층에서 발생하는 예외를 반드시 받아서 상위 계층 추상화 수준에 맞는 예외로 바꿔서 던져야 한다
- Throwable.initCause 메서드를 호출하면 하위계층 예외를 연결 할 수 있다
- 프로그램 안에서 예외의 원인데 접근할 수 있을 뿐 아니라 최초에 발생한 예외의 스택 추적 정볼르 상위 계층 예외에 통합할 수 있게 된다
- 아무 생각 없이 아래 계층에서 생긴 예외를 밖으로 전달하기만 하는 것보다 예외를 변환하여 던지는 것이 낫지만 남용하면 안 된다
- 하위 계층에서 예외가 생기기 않도록 하는 것이 가장 좋다
- 하위 계층 메서드에서 예외가 발생하는 것을 막을 수 없다면 하위 계층에서 생기는 문제를 상위 계층 메서드 호출자로부터 격리시키는 것이다
- 로그를 남기고 하위 계층에서 발생한 옝외를 어떤 식으로 처리해버리는 것이다
규칙62 메서드에서 던져지는 모든 예외에 대해 문서를 남겨라
- Checked예외는 독립적으로 선언하고 해당 예외가 발생하는 상황은 Javadoc @throws 태그를 사용해서 정확하게 발곃라
- throws Exception 이라고 선언하거나 throws Throwable이라고 선언하는 것은 피해야 한다
- UnChecked예외까지 선언할 필요는 없으나 주의해서 문서로 남겨 놓으면 좋다
- Javadoc @throws 태그를 사용해서 메서드에서 발생 가능한 모든 UnChecked예외데 대한 문서를 남겨라
- 메서드 선언부의 throws 뒤에 무점검 예외를 나열하진 마라
- 동일한 예외를 던지는 메서드가 많다면 메서드마다 문서를 만드는 대신 해당 예외에 대한 문서는 클래스의 문서화 주석에 남겨도 된다
- 메서드가 던질 가능성이 있는 모든 예외는 문서로 남기는 것이 좋다
규칙63 어떤 오류인지를 드러내는 정보를 상세한 메시지에 담으라
- 오류 정보를 포착해 내기 위해서는 오류의 상세 메시지에 예외에 관계된 모든 인자와 필드의 값을 포함시켜야 한다
- 가독성보다는 내용이 훨씬 중요하다
규칙64 실패 원자성 달성을 위해 노력하라
- 메서드 호출이 정상적으로 처리되지 못한 객체의 상태는 메서드 호출 전 상태와 동일해야 한다
- 이 속성을 만족하는 메서드는 실패 원자성(failure atomicity)을 갖추었다고 한다
- 실패 원자성을 달성하는 방법은 다음과 같다
- 변경 불가능 객체로 설계하라
- 변경 가능한 객체의 경우에는 실제 연산을 수행하기 전에 인자 유효성을 검사하라
- 실패할 가능성이 있는 코드를 전부 객체 상태를 바꾸는 코드 앞에 배치하라
- 연산 수행 도중에 발생하는 오류를 가로채는 복구 코드를 작성하라
- 객체의 임시 복사본상에서 필요한 연산을 수행하고 연산이 끝난 다음에 임시 복사본의 내용으로 객체 상태를 바꾸는 것이다
- 예외와는 달리 오류(error)는 복구가 불가능하며 오류를 던지는 경우에는 실패 원자성을 보존하려 애쓸 필요가 없다
- 실패 원자성을 달성하기 위해 비용이나 복잡성이 심각하게 늘어나는 것은 바람직하지 않다
규칙65 예외를 무시하지 마라
- 빈 catch 블록 안에는 예외를 무시해도 괜찮은 이유라도 주석으로 남겨 두어야 한다
병행성
규칙66 변경 가능 공유 데이터에 대한 접근은 동기화하라
- 쓰레드를 중지시킬 때 Thread.stop은 절대로 이용하지 마라
- 안전성이 결여되어 있어 데이터가 망가질 수 있다
- 읽기 연산과 쓰기 연산에 전부 적용하지 않으면 동기화는 아무런 효과도 없다
- volatile은 어떤 쓰레드건 가장 최근에 기릭된 값을 읽도록 보장한다
규칙67 과도한 동기화는 피하라
- 동기화가 적용된 영역 안에서는 재정의 가능 메서드나 클라이언트가 제공한 함수 객체 메서드를 호출하지 마라
- 동기화 영역이 존재하는 클래스 관점에서 보면 그런 메서드는 무슨 일을 하는지 알 수도 없고 제어할 수도 없다
- 동기화 영역 안에서 호출하게 되면 예외나 교착상태, 데이터 훼손이 발생 할 수 있다
규칙68 쓰레드보다는 실행자와 태스크를 이용하라
규칙69 wait나 notify 대신 병행성 유틸리티를 이용하라
- wait나 notify를 정확하게 사용하는 것이 어렵기 대문에 고수준 유틸리티들을 이용해야 한다
- Collections.synchronizedMap이나 Hashtable 대신 ConcurrentHashMap을 사용하도록 하자
- 특정 구간의 실행시간을 잴 대는 System.currentTimeMillis 대신 System.nanoTime을 사용해야 한다
규칙70 쓰레드 안전성에 대해 문서로 남겨라
- synchronized 키워드는 메서드의 구현 상세에 해당하는 정보이며 공개 API의 일부가 아니다
- 위 이유로 Javadoc이 만드는 문서에는 synchronized 키워드가 들어가 있지 않다
- 병렬적으로 사용해도 안전한 클래스가 되려면 어떤 수준의 쓰레드 안전성을 제공하는 클래스인지 문서에 명확하게 남겨야 한다
- 변경 불가능(immutable)
- 이 클래스로 만든 객체들은 상수다
- 외부적인 동기화 메커니즘 없이도 병렬적으로 이용 가능하다
- String, Long, BigInteger 등이 이에 해당한다
- 무조건적 쓰레드 안전성(unconditionally thread-safe)
- 이 클래스의 객체들은 변경이 가능하지만 적절한 내부 동기호 ㅏ메커니즘을 갖추고 있어서 외부적으로 동기화 메커니즘을 적용하지 않아도 병렬적으로 사용 할 수 있다
- Random, ConcurrentHashMap 등이 이에 해당한다
- 조건부 쓰레드 안전성(conditionally thread-safe)
- 무조건적 쓰레드 안전성과 거의 같은 수준이나 몇몇 쓰레드는 외부적으로 동기화가 없이는 병렬적으로 사용할 수 없다
- 이런 객체의 반복자(iterator)는 외부적 동기화 없이 병렬적으로 이용할 수 없다
- 쓰레드 안전성 없음
- 이 클래스의 객체들은 변경 가능하다
- 객체들을 병렬적으로 사용하려면 클라이언트는 메서드를 호출하는 부분을 클라이언트가 선택한 외부적 동기화 수단으로 감싸야 한다
- ArrayList나 HashMap 같은 일반 용도의 컬렉션 구현체들이 이에 해당한다
- 다중 쓰레드에 적대적(thread-hostile)
- 메서드를 호출하는 부분을 외부적 동기화 수단으로 감싸더라도 안전하지 않다
- 이런 클래스가 되는 것은 보통 동기화 없이 정적 데이터를 변경하기 때문이다
- 변경 불가능(immutable)
- 무조건적 쓰레드 안전성을 제공하는 클래스를 구현하는 중이라면 메서드를 synchronized로 선언하는 대신 private 락 객체를 이용하면 어떨지 따져보라
- 락 객체를 이용하면 클라이언트나 하위 클래스가 동기화에 개입하는 것을 막을 수 있다
- 다음번 릴리스에는 좀 더 복잡한 병생성 제어 전략도 쉽게 채택할 수 있게 되낟
규칙71 초기화 지연은 신중하게 하라
- 대부분의 경우 지연된 초기화를 하느니 일반 초기화를 하는 편이 낫다
- 성능 문제 대문에 정적 필드 초기화를 지연시키고 싶을 때는 초기화 담당 클래스를 적용하라
- 클래스가 실제로 사용되는 순간에 초기화된다는 점을 이용한 것이다
- FieldHolder 클래스는 FieldHolder.field가 처음으로 이용되는 순간, getField 메서드가 처음 호출되는 순간 초기화된다

- 최신 VM은 클래스를 초기화하기 위한 필드 접근은 동기화한다
- 성능 문제 때문에 객체 필드 초기화를 지연시키고 싶다면 이중 검사를 사용하라
- 이미 초기화된 필드에는 락을 걸지 않으므로 필드는 반드시 volatile로 선언해야 한다

- 만약 여러번 초기화되어도 상관없는 객체 필드의 초기화를 지연시키고 싶을 때 두 번째 검사는 없애버려도 된다

규칙72 쓰레드 스케줄러에 의존하지 마라
- 정확성을 보장하거나 성능을 높이기 위해 쓰레드 스케줄러에 의존하는 프로그램은 이식성이 떨어진다
- 다른 쓰레드에 비해 충분한 CPU시간을 받지 못하는 쓰레드가 있더라도 Thread.yield를 호출해서 문제를 해결하려고는 하지 마라
- 쓰레드 우선순위는 자바 플랫폼에서 가장 이식성이 낮은 부분 가운데 하나다
- Thread.yield 대신 Thread.sleep(1)을 사용해야 한다
- Thread.sleep(0)은 바로 리턴하기 때문에 사용하면 안된다
규칙73 쓰레드 그룹은 피하라
- 쓰레드 그룹은 이제 폐기된 추상화 단위다
직렬화
규칙74 Serializable 인터페이스를 구현할 때는 신중하라
- Serializable은 클래스를 릴리스하고 나면 클래스 구현을 유연하게 바꾸기 어려워진다
- Serializable은 버그나 보안 취약점이 발생할 가능성이 높아진다
- 계승을 염두에 두고 설계하는 클래스는 Serializable을 구현하지 않는 것이 바람직하다
- 계승을 고려해 설계된 클래스로는 다음과 같은 것들이 있다
- Throwable
- 원격 메소드 호출(RMI)시 발생하는 예외를 서버에서 클라이언트로 전달하기 위한 것
- Component
- HttpServlet
- 세션 상태를 캐시하기 위해 Serializable을 구현하고 있다
- Throwable
- 객체 필드가 기본값으로 초기화되면 위배되는 불변시기 있는 경우에는 readObjectNoData 메서드를 클래스에 반드시 추가하여 이 메스드에서 예외를 발생시키도록 해야한다
- 기본값으 정수 자료형인 경우에는 0, boolean 인 경우에는 false, 객체 참조 자료형인 경우에는 null

- 인터페이스는 가급적 Serializable을 계승하지 말아야 한다
- 내부 클래스는 Serializable을 구현하면 안 된다
- 내부 클래스에는 바깥 객체에 대한 참조를 보관하고 바깥 유효범위의 지역 변수 값을 보관하기 위해 컴파일러가 자동으로 생성하는 필드가 있다
- 정적멤버클래스는 Serializable을 구현할 수 있다
규칙75 사용자 지정 직렬화 형식을 사용하면 좋을지 따져 보라
- 어떤 직렬화 형식이 적절할지 따져보지도 않고 기본 직렬화 형식을 그대로 받아들이지 마라
- 기본 직렬화 형식은 그 객체의 물리적 표현이 논리적 내용과 동일할 때만 적절하다
- 기본 직렬화 형식이 만족스럽다 하더라도 불변식이나 보안 조건을 만족시키기 위해서는 readObject 메서드를 구현해야 마땅한 경우도 많다
- 객체의 물리적 표현 형태가 논리적 내용과 많이 다를 경우 기본 직렬화 형식을 그대로 받아들이면 아래의 네 가지 문제가 생긴다
- 공개 API가 현재 내부 표현 형태에 영원히 종속된다
- 너무 많은 공간을 차지하는 문제가 생길수 있다
- 너무 많은 시간을 소비하는 문제가 생길 수 있다
- 기본 직렬화 로직은 객체 그래프 토폴로지 정보를 이해하지 못하므로 많은 양의 그래프 순회를 해야한다
- 스택오버플로우 문제가 생길 수 있다
- 기본 직렬화 로직은 재귀적인 객체 그래프 순회를 필요로 하는데 이 과정에서 스택오버플로우 문제가 발생할 수 있다
- 객체의 모든 필드가 transient일 때는 defaultWriteObject나 defaultReadObject를 호출하지 않는 것도 가능하긴 하지만 권장사항은 아니다
- 모든 객체 필드가 transient이더라도 defaultWriteObject를 호출하면 직렬화 형식이 바뀌며 그 결과로 유연성이 크게 향상된다
- 나중에 transient가 아닌 필드를 추가하더라도 상위 및 하위 호환성이 유지된다
- 객체의 논리적 상태를 구성하는 값이라는 확신이 들기 전에는 비-transient 필드로 만들어야겠다는 결정을 내리지마라
- 객체를 직렬화 할 때는 객체의 상태 전부를 읽는 메서드에 동기화 수단을 반드시 적용해야한다
- 어떤 직렬화 형식을 이용하건 직렬화 가능 클래스를 구현할 때는 UID를 명시적으로 선언해야한다
- UID 때문에 생길 수 있는 잠재적 호환성 문제가 사라진다
- UID를 지정하지 않으면 실행시간에 UID를 만드느라 시간이 많이 걸리는 계산을 하게 된다
규칙76 readObject 메서드는 방어적으로 구현하라
- 객체를 역으로 직렬화할 때는 클라이언트가 가질 수 없어야 하는 객체 참조를 담은 모든 필드를 방어적으로 복사하도록 해야 한다
- 유효성 검사 이전에 방어적 복사를 시행해야한다
- 1.4부터는 방어적 복사 없이도 악의적 객체 참조 공격을 막을 수 있도록 고안된 writeUnshard와 readUnshared 메서드가 ObjectOuputstream에 추가되었지만 사용하지는 마라
- 방어적 복사를 하는 것보다 빠르긴 하겠지만 필요한 안정성을 제공하지 못한다
- 복잡한 공격에는 취약하다
- 불변식을 검사해서 위반된 사실이 감지될 경우 InvalidObjectException을 던져라
- 만일 객체를 완전히 역직렬화 한 다음에 전체 객체 그래프의 유효성 검사를해야 한다면 ObjectInputValidation 인터페이스를 이용하라
- 직접적이건 간접적이건 재정의 가능 메서드를 호출하지 마라
규칙77 개체 통제가 필요하다면 readResolve 대신 enum 자료형을 이용하라
- readResolve를 이용하면 readObject가 만들어낸 객체를 다른 것으로 대체할 수 있다
- 객체 클래스에 readRersolve 메서드가 정의되어 있는 경우 역직렬화가 끝나서 만들어진 객체에 대해 이 메서드가 호출되고 새로 만들어진 객체 대신 이 메서드가 반환하는 객체가 사용자에게 돌아간다
- readResolve 호출이 끝나면 readObject가 만든 객체에 대한 참조는 사라지므로 바로 GC가 가능해진다
- 객체 통제를 위해 readResolve를 활용할 때는 모든 객체 필드를 반드시 transient로 선언해야 한다
- 개체 통제를 위해 readResolve를 사용하는 대신 enum으로 구현하면 선언된 상수 이외에는 다른 객체는 존재할 수 없다는 확실한 보장이 생긴다
- JVM이 해주는 보장이므로 빋을 수 있다
- readResolve 메서드의 접근 권한은 중요하다
- final 클래스에 readResolve 메서드를 두는 경우에는 반드시 private으로 선언해야 한다
- pirvate라면 하우 ㅣ클래스에는 적용되지 않는다
- protected나 private이라면 readResolve를 재정의하지 않은 모든 하위 클래스에 적용될 것이다
규칙78 직렬화된 객체 대신 직렬화 프락시를 고려해 보라
- 직렬화 프락시(serialization proxy)는 다음과 같이 설계한다
- 바깥 클래스를 인자 자료형으로 사용하는 생성자를 하나만 갖는 private static 중첩 클래스를 만든다
- 중첩 클래스는 직렬화 가능해야한다
- 중첨 클래스의 생성자에서는 인자의 데이터를 복사하기만 한다

- 직렬화 프락시를 이용하면 Period의 필드를 final로 선언할 수 있고 변경 불가능 클래스로 만들 수 있다
- 직렬화 도중에 명시적으로 유효성 검사를 할 필요도 없다
책
- http://book.naver.com/bookdb/book_detail.nhn?bid=8064518
Published 08 August 2016