The Google File System
1 INTRODUCTION
- 빠르게 증가하는 데이터 처리에 대한 요구를 만족시키기 위해 고안된 시스템
- 기존의 파일 시스템과의 차별점
- 시스템에서는 언제든지 오류가 발생할 수 있다고 생각한다
- 모니터링, 오류 검출, Fault Tolerance, 복구 시스템이 갖춰져있다
- 파일이 크다
- IO 처리, 블럭 크기에 대한 것들이 재검토되었다
- 파일에 기존 데이터를 덮어쓰기보다는 새로운 데이터를 추가한다(append)
- 새로운 데이터를 추가하여 파일을 수정함으로써 성능과 원자성을 보장할 수 있다
- 어플리케이션과 파일시스템 API를 통합 설계하는 것이 유연성을 증가시키면서 시스템 전체적으로 이익을 가져온다
- 시스템에서는 언제든지 오류가 발생할 수 있다고 생각한다
2 DESIGN OVERVIEW
2.1 Assumtions
- 전체 시스템은 종종 오류를 발생 시킬 수 있는 값 싼 시스템들로 구성된다
- 모니터링, 오류 검출, Fault Tolerance, 복구 시스템이 갖춰져 있어야 한다
- 수만개의 파일을 저장한다
- 대용량파일을 효율적으로 관리한다
- 작은 용량의 파일도 관리가 가능하지만 최적화하진 않는다
- 큰 범위를 읽기 위한 streaming read 와 작은 범위를 읽기 위한 radom read를 지원한다
- 파일에 커다란 데이터를 추가하기 위한 wrtie 기능을 지원한다
- 여러 클라이언트가 동시에 같은 파일에 데이터를 쓸수있는 방법이 제공되어야 한다
- 높은 네트워크 대역폭이 있어야 한다
2.2 Interface
- 파일은 디렉토리내에서 계층 구조로 관리된다
- 파일은 경로명으로 구분된다
- create, delete, open, close, read, write 기능을 제공한다
- snapshot 기능 제공
- 낮은 비용으로 파일이나 디렉토리를 복사하는 기능
- Record append 기능 제공
- 원자성을 보장하며 여러 클라이언트가 동일한 파일에 동시에 데이터를 추가할 수 있도록 하는 기능
2.3 Architecture
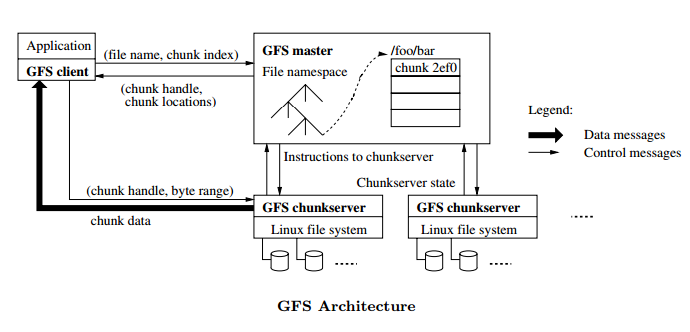
- GFS는 하나의 마스터 서버와 여러개의 chunk서버로 구성된다
- 파일은 고정된 크기의 chunk로 나뉘어진다
- 각각의 chunk는 유니크한 64비트의 chunk handle에 의하여 구분된다
- chunk handle은 chunk가 생성될때 마스터에서 할당
- 마스터 서버는 파일에 대한 메타데이터를 관리한다
- 메타데이터에는 다음과 같은 데이터가 포함된다
- namespace
- access control information
- 파일에 매핑된 chunk의 정보
- chunk의 현재 위치
- 메타데이터에는 다음과 같은 데이터가 포함된다
- 마스터 서버는 chunk들에 대한 관리를 한다
- chunk 할당
- chunk 수거
- 다른 chunk서버로 chunk 이관
- 마스터 서버는 주기적으로 chunk서버들과 하트비트를 메세지를 통하여 명령을 전달하거나 chunk서버의 상태를 확인한다
- 클라이언트는 메타데이터에 관련된 작업을 요청할때는 마스터 서버와 통신한다
- 클라이언트는 실제 데이터 조작에 관련된 작업을 요청할때는 chunk서버와 직접 통신한다
- chunk서버와 클라이언트는 파일을 캐싱하지 않는다
- 클라이언트에서 메타데이터는 캐싱할 수 있다
- chunk서버에는 이미 리눅스 버퍼 캐쉬에서 캐싱하고 있어서 별도로 캐싱할 필요가 없다
2.4 Single Master
- 단일 마스터 구조이기 때문에 시스템 구조가 단순화된다
- chunk 배치/복제에 대한 결정을 쉽게 할 수 있다
- 병목이 발생하지 않도록 read/write와 연관된 동작은 최소화 해야한다
- 클라이언트는 절대 마스터 노드를 통하여 read/write를 해선 안된다
- 클라이언트는 마스터에게 작업하기 위한 chunk서버의 위치를 물어볼 수 있다
- 마스터가 알려준 chunk서버에 대한 정보는 클라이언트에서 캐싱할 수 있다
- read 동작 과정
- 클라이언트는 파일 이름과 정해진 chunk size를 이용하여 바이트 오프셋을 chunk index로 변환하여 마스터에게 전송한다
- 마스터는 chunk handle과 chunk 위치들을 클라이언트에게 알려준다
- 클라이언트는 파일 이름과 chunk index를 키로 이용하여 이 chunk 위치 정보를 캐싱한다
- 클라이언트는 가장 가까이있는 chunk에게 read 요청을 보낸다
- read 요청에는 chunk handle과 읽어들일 byte 범위가 포함되어 있다
- 클라이언트에서 동일한 chunk에 대한 요청은 캐싱 시간이 만료되기 전까지 또는 파일을 다시 열기 전까지는 마스터에게 청크에 대한 정보를 묻지 않고 직접 요청한다
2.5 Cunk Size
- chunk size는 중요한 파라미터이다
- 일반적인 파일 시스템의 block size 보다는 크게 chunk size를 64MB로 지정하고있다
- 각각 chunk에 대한 replication은 일반적인 리눅스 파일 형태로 저장된다
- 필요에 따라 64MB 보다 크게 확장 될 수 있다
- Lazy space allocation 기법은 내부 단편화를 방지 할 수 있다
- chunk size 를 크게 지정함으로써 얻는 장점
- read/write를 동일한 chunk에 대해서만 처리할 가능성이 높기 때문에 마스터와 계속해서 통신할 필요가 없다
- read/write를 동일한 chunk에 대해서만 처리할 가능성이 높기 때문에 chunk 서버에 연결된 tcp 커넥션을 유지하여 네트워크 비용을 줄인다
- 마스터에서 관리되는 메타데이터의 양을 줄일 수 있다
- chunk size 를 크게 지정함으로써 얻는 단점
- 작은 파일은 적은 청크(아마도 한개)로 이루어질 것이다
- 클라이언트들이 같은 파일에 접근하려한다면 이 파일은 hot spot이 될 것이다
- 작은 파일은 적은 청크(아마도 한개)로 이루어질 것이다
2.6 Metadata
- 마스터 서버는 3가지 타입의 메타데이터를 저장한다
- 파일과 chunk의 namespace
- 파일과 chunk의 매핑 정보
- chunk replication에 대한 위치 정보
- 모든 메타데이터는 마스터 서버 메모리에 저장되고 관리된다
- namespace와 파일-chunk 매핑 정보는 마스터 서버의 로컬 디스크에 로깅되고 원격 서버에 복사되어 관리된다
- 로그를 이용함으로써 마스터 서버에 크래쉬가 발생하더라도 쉽고 간단하게 복구 시킬 수 있다
- 마스터 서버는 chunk의 위치 정보를 로그와 같이 영구적으로 보관 가능한 방법으로 저장하지 않는다
- chunk서버가 실행될때 (클러스터에 참여될때) 마스터 서버는 chunk서버에게 현재 가지고 있는 chunk의 정보를 물어본다
2.6.1 In-Memory Data Structures
- 메타데이터가 로컬 메모리에 저장되기때문에 마스터 서버는 빠르게 동작 할 수 있다
- 메타데이터를 통해서 청크의 상태들을 백그라운드에서 주기적으로 효율적으로 검사할 수 있다
- chunk의 상태를 주기적으로 검사함으로써 다음과 같은 것들을 할 수 있다
- chunk garbage collection
- chunk 서버에 문제 발생시 re-replication
- chunk 서버의 디스크 공간 사용 밸런싱을 위한 migration
- 메타데이터의 저장 가능 개수는 마스터 서버의 메모리 크기에 따라 달라진다
- 마스터 서버에 64MB의 청크들이 아닌 64byte 정도의 메타 데이터만 저장하기 때문에 크게 문제가 되진 않을 것이다
- 마지막 chunk를 제외한 대부분의 chunk들은 꽉차 있을 것이다
- 파일 namespace는 64byte보다 적은 공간을 차지한다 (prefix를 압축한 상태로 파일명을 저장)
2.6.2 Chunk Locations
- 마스터 서버는 chunk의 replica가 어디에 저장되어 있는지에 대한 정보를 영구적으로 보관하지 않는다
- chunk 서버가 실행될때 chunk에 대한 정보를 물어보고 가져온다
- chunk 서버가 실행 된 이후에는 chunk에 대한 관리(replica, migration,,등)를 하트비를 통하여 마스터에서 주가되어 하기 때문에 chunk 정보를 최신 상태로 유지 가능하다
2.6.3 Operation Log
- operation log는 중요한 정보이기 때문에 안전하게 저장해야 한다
- operation log는 중요한 메타데이터가 변경된 이력을 포함한다
- 메타데이터를 영구적으로 보관한다
- 논리적인 타임 라인을 기록함으로써 동시에 요청된 operation에 대한 순서를 확인 할 수 있다
- 파일, chunk 그리고 버전 등등 이것들이 생성됬을 당시의 논리적인 시간으로 가지고 구분된다
- operation log를 마스터 서버의 로컬이아닌 다른 머신에 replica를 만들어둬야한다
- 메타데이터에 대한 변경/저장이 완료 될때 까지 변경 정보를 클라이언트에게 반영해선 안된다
- operation log를 로컬/원격에 모두 저장이 완료 되었을때 클라이언트요 청에 대한 응답을 준다
- 마스터 서버는 실행시에 operation log를 통하여 마스터 서버 내에서 관리하던 파일 시스템들의 상태를 복구 할 수 있다
- 마스터 서버 실행 시간을 줄이기 위해 operation log는 작게 유지한다
- operation log가 특징 크기를 넘을때마다 체크포인트를 생성한다
- 체크포인트는 namespace를 검색하는데 불필요한 파싱을 없애고 메모리에 직관적으로 매핑되게 하기 위해서 B-tree 형태로 생성된다.
- 오래된 체크포인트는 자연스럽게 제거된다
- 체크포인트 생성에 실패하더라도 마스터 서버의 recovery 관련 코드에서 정상적인 체크포인트가 아니라는걸 판단 가능하기때문에 문제가 되지 않는다
2.7 Consistency Model
2.7.1 Guarantees by GFS
- 파일 namespace 변경이나 파일생성과 같은 작업은 원자성 가진다
- 이 작업들은 마스터에서만 실행된다
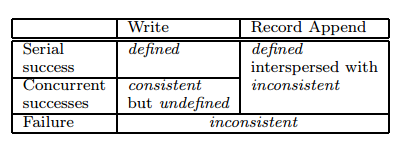
- 데이터 변경 후 파일 영역에 대한 상태는 다음과 같은 상황에 따라 달라진다
- 변경 작업의 종류
- 변경 성공 여부
- 동시에 진행된 다른 변경 작업의 결과
- 파일 영역에 대한 상태
- consistent
- 모든 클라이언트가 replica 상관 없이 동일한 데이터를 보는 상태
- defined
- consistent 상태에서 클라이언트가 요청한 write 작업이 완료된 상태
- 동시에 요청된 변경 작업이 완료되었을때 변경된 부분은 defined 상태가 된다
- 동시에 요청된 변경 작업은 consitent 하지만 undefined 상태 일 수 있다
- 모든 클라이언트는 동일한 데이터를 보지만 일부 변경이 적용되지 않은 상태일 수 있다
- inconsistent
- 변경에 실패한 상태
- 각각의 클라이언트는 서로 다른 데이터를 보게 된다
- 변경에 실패한 상태
- consistent
- 파일 변경 작업이 chunk replica에 정상적으로 적용되었는지는 chunk version number를 가지고 판단한다
- 파일 변경 작업이 제대로 이루어지지 않은 chunk 서버에 대해서는 garbage collect 과정에서 수거된다
- 클라이언트가 chunk 서버의 위치를 물어볼때에도 해당 chunk서버는 포함되지 않는다
- 클라이언트에 해당 chunk 서버의 위치가 캐싱되어 있는 정보는 일정 시간이 지난 경우나 파일 open 요청이 있을 경우 캐시에서 삭제된다
- 대부분의 작업은 append이기 때문에 replica에 문제가 생겼을경우 클라이언트는 제대로된 결과를 받지 못하게되어 재시도하거나 마스터에게 chunk정보를 다시 요청하게 된다
- 마스터는 chunk서버에 문제가 있는지 확인하기위해 handshake를 주기적으로 요청한다
- 체크섬을 통하여 데이터에 문제가 발생했는지 확인한다
- chunk서버에서 문제가 발생하게 되면 가능한 빨리 정상적인 다른 chunk서버로 부터 데이터를 복사하여 복구한다
2.7.2 Implications for Applications
- 파일에 overwrite를 하지 않고 append를 한다
- checkpoint를 생성한다
- self-validating
- self-identifying
3 SYSTEM INTERACTIONS
- 모든 동작에대해 마스터의 관여가 최소화되도록 디자인 되었다
3.1 Leases and Mutation Order
- mutation은 파일 데이터나 chunk의 metadata를 변경하는 동작이다
- write와 append가 이에 속한다
- lease를 이용하여 replica들 사이에 consistent를 유지하도록 한다
- 마스터는 replica중 primary를 선정하여 chunk lease를 할당한다
- primary는 chunk들 사이에 mutation 작업순서를 지정한다
- primary를 제외한 replica들은 이 순서에의해 muatation이 된다
- lease는 마스터의 오버헤드를 최소화하기 위해 고안된 방법이다
- lease의 타임아웃은 60초 이지만 primary가 마스터에게 시간 연장을 요청할 수 있다
- primary가 마스터에게 lease 시간에 대해 요청하는 패킷은 하트비트 패킷 뒤에 붙어서 보내진다(piggyback)
-
마스터와 primary의 통신이 끊기더라도 마스터는 이전 lease가 만료된 이후에 새로운 lease를 생성하여 다른 replica에게 요청 할 수 있다
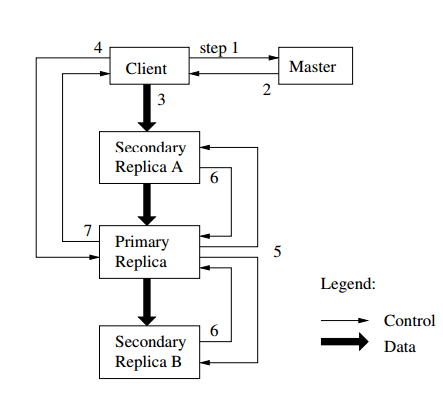
- 클라이언트는 마스터에게 어떤 chunk서버가 lease를 소유하고 있는지 물어본다
- 만약 lease를 소유하고있는 chunk서버가 없을 경우 마스터는 chunk서버를 하나 지정하여 lease를 할당한다
- 마스터는 클라이언트에게 primary(chunk서버)와 다른 2대의 secondary(chunk서버) 정보를 전달해준다
- 클라이언트는 이 정보를 캐싱한다
- 클라이언트에서 primary나 secondary 에 연결이 되지 않을 경우 마스터에게 다시 물어보게 된다
- 클라이언트는 primary, secondary 상관없이 데이터를 전송한다
- 데이터를 수신한 chunk서버는 다른 chunk서버에도 데이터를 전달한다
- chunk서버는 수신된 데이터를 내부 LRU 캐쉬버퍼에 저장한다
- 데이터가 처리되거나 오래되면 캐쉬 버퍼에서 삭제한다
- 클라이언트가 데이터 전송을 완료하면 primary에게 write 요청을 보낸다
- primary는 연속된 serial number를 모든 mutation작업에 할당을 하게된다
- primary 내부에서 serial number순서대로 mutation을 적용한다
- primary 는 write 요청을 모든 secondary chunk서버에게 전달한다
- 각각의 secondary chunk서버는 muatation 작업을 적용한다
- secondary chunk서버 역시 serial number 순서대로 mutation이 적용된다
- secondary chunk서버들은 작업이 완료되면 primary에게 응답을 준다
- primary는 작업의 결과를 클라이언트에게 알려준다
- 오류가 발생할 경우 발생한 오류에 대한 정보를 클라이언트에게 알려준다
- 오류가 발생한 경우 변경된 파일 region은 inconsistent 상태가 된다
- 클라이언트는 오류가 발생하면 해당 작업을 재요청하게 된다 (앞 단계들을 반복)
3.2 Data Flow
- 네트워크 병목을 피하기 위해 각각의 서버들은 데이터를 전달할때 가까운 서버에게 전달한다
- 클라이언트가 서버S1에게 데이터를 전달하면 S1은 자신에게서 가장 가까운 서버로 데이터를 전달한다
- IP 주소를 가지고 서버의 거리를 계산한다
- B bytes 를 R개의 chunk서버에 전송하는 비용 : B/T + RL
- T : 네트워크 Throughput
- L : Latency = 1/T
- 네트워크 T가 100Mbps 일 경우 L은 1ms
- 이상적인 환경에서 1MB는 80ms내에 전달이 완료된다
3.3 Atomic Record Appends
- 데이터를 추가할떄 원자성을 유지하기 위해 record append 기능을 제공한다
- 기존에는 클라이언트가 데이터를 적을 위치(offset)를 정했다
- 이 방식은 동시에 여러 데이터가 쓰여질때 원자성을 유지하지 못한다
- record append는 클라이언트가 데이터만 제공하고 GFS에서 파일 위치(offset)를 지정하고 원자성을 유지하면서 데이터를 추가한다
- 데이터를 추가한 이후에는 클라이언트에게 파일 offset을 리턴한다
- record append 는 primary(chunk서버)에서 추가적인 동작을 할뿐 mutation의 일종이다
- record append 과정
- 클라이언트가 chunk서버에 데이터를 보내고 primary에 write 요청을한다
- primary는 record를 추가하려는 chunk의 크기가 최대 크기(64MB)를 넘었는지 확인한다
- record append는 fragmentation의 최악인 경우를 막기 위해 최소 chunk 최대 크기의 1/4만큼의 데이터를 유지하도록한다
- 패딩을 넣어서 1/4크기를 만든다
- record append에 성공하면 클라이언트에게 응답을 준다
- record append에 실패하면 클라이언트는 재시도를 해야한다
- record append가 한번이라도 실패하면 전체 혹은 일부분의 데이터가 중복될 수 있다
- GFS는 파일에 중복된 데이터가 생기는 것을 막아주지 않는다
- ㅂ1해준다
- GFS는 파일에 중복된 데이터가 생기는 것을 막아주지 않는다
3.4 Snapshot
- snapshot은 현재 진행중인 작업(mutation)에 상관없이 즉시 파일이나 디렉토리의 사본을 만드는 기능이다
- 사용자들은 이 기능을 사용하여 빠르고 쉽게 데이터의 사본이나 checkpoint를 만들 수 있다
- 마스터가 snapshot 생성 요청을 받게되면 다음과 같은 일을 한다
- 아직 처리되지 않은 lease에 대해서는 중지 시킨다
- lease를 중지하게되면 write 작업을 할떄 마스터를 통해 lease를 획득해야한다
- lease들을 중지시킴으로써 마스터가 snapshot 생성을 할 수 있도록 한다
- 메모리내에 metadata를 복사한다
- 한 chunk를 가리키고 있는 metadata는 2개가 된다
- 아직 처리되지 않은 lease에 대해서는 중지 시킨다
- snapshot은 copy-on-write 기법을 활용하여 구현되었다
- snapshot 요청 후에 클라이언트가 chunk C에 write 요청을 보낼 경우 다음과 같이 동작된다
- 마스터는 chunk C의 현재 reference count가 1보다 큰것을 확인한다
- snapshot 생성 요청되었을떄 metatdata가 복사되어 reference count 는 2가 되었다
- chunk C를 가지고 있는 각 chunk서버에게 C'을 만들도록 한다
- 데이터 복사는 각각의 로컬에서 이루어진다
- 마스터는 새로운 chunk C'에게 lease를 할당하고 클라이언트에게 응답을 보낸다
- 클라이언트는 자신이 전달받은 chunk의 정보가 새로 생성된 것인지 알지 못한다
- 마스터는 chunk C의 현재 reference count가 1보다 큰것을 확인한다
4 MASTER OPERATION
4.1 Namespace Management and Locking
4.2 Replica Placement###
4.3 Creation, Re-replication, Rebalancing
4.4 Gabage Collection
4.4.1 Mechanism
4.4.1 Discussion
4.5 Stale Replica Detection
5 FAULT TOLERANCE AND DIAGNOSIS
5.1 High Availability
5.1.1 Fast Recovery
5.1.2 Chunk Replication
5.1.3 Master Replication
5.2 Data Integrity
5.3 Diagnostic Tools
원문
- http://static.googleusercontent.com/media/research.google.com/ko//archive/gfs-sosp2003.pdf
Published 24 January 2016